News (2023)
Back To:
Amdahl's Law and Large Computers: (December 27, 2023) - permalink
I mentioned in my last post that I'd talk about Amdahl's Law, so here we go.
Back in November, someone with some very large servers reported a bug where y-cruncher would hang on his 256-core (512-vcore) AMD Bergamo system while running large swap mode computations. By "hang", the program is neither using CPU nor performing disk I/O. However, these hangs were not permanent and the program would always recover after waiting a long time (many minutes).
The program hanging for a long time then recovering is baffling as it does not match the profile of any usual software bug. If there's a deadlock, it hangs forever. If there's an infinite loop, you should see CPU or I/O usage. Programs don't just break and fix themselves. My initial suspicion is that some I/O operation was stalled due to a hardware issue, but Task Manager shows 0% busy on all SSDs. So the I/O was truly idle.
To help debug this, I was given remote access. But I was only able to reproduce the hang once and was not able to get a proper stack trace before it recovered and resumed normal computation. However, I did learn something important: During the hang, the CPU usage was not completely zero. y-cruncher was actually using about 0.2% CPU - which is almost immeasurable and easily mistaken for zero.
So the program didn't actually hang. It was running single-threaded on 512 vcores. If it didn't hang, then what was the program doing? Could this be a really bad case of Amdahl's Law?
However, there's a problem with this theory. While there are places in y-cruncher that remain unparallelized, they are not compute-intensive and are usually simple things like a memcpy() or a carry-propagation chain. Given that the machine has 1.5 TB of ram, simple operations like these do not take 30 minutes to traverse 1.5 TB of data on one thread as had been observed. Something isn't adding up.
Given that I needed to focus on testing v0.8.3 for its release, my attention shifted away from investigating this further. But while this was all going on, I had been playing with SSD arrays on a new test system. The testing for v0.8.3 consisted of numerous large computations in swap mode with different settings. But just in case... I kept a Remote Desktop window open to the machine on a separate monitor while I went about my daily routine.
And after a few days, I saw this:
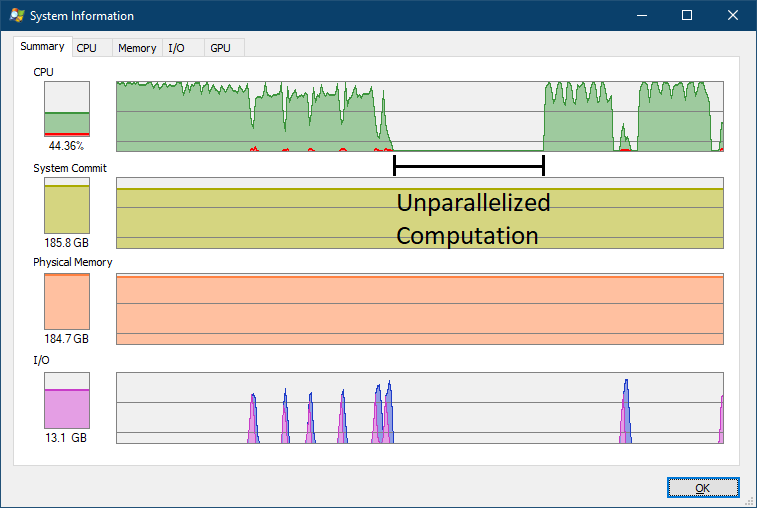 |
Amdahl's Law being exposed on a consumer desktop. The effect on large (many-core) servers is many times worse. |
Here, the processor is "only" a 16-core (32-vcore) Ryzen 7950X instead of the 256-core Bergamo system where the problem was originally reported from. But even with this smaller system there was a clear 80 seconds of single-core CPU usage.
Extrapolating this to the 512-vcore Bergamo system:
- The 80 seconds of single-core CPU usage becomes closer to 15-20 minutes with the 1.5 TB of ram and the lower clock speeds. This is similar to the hang durations that were originally reported.
- The non-parallelized section will show as 0.02% CPU usage due to 1 core being divided across 512 vcores. This is visually the same as zero on the graph.
- The parallelized parts in the graph above would be horizontally compressed by a factor of ~8x due to the massive compute power of the 256 cores. So the unparallelized portion would appear much longer and span 30 minutes - multiple times the width of the graph.
Combined, these 3 things would easily create the illusion that the program isn't doing anything (i.e. hanging).
So it seems that I managed to reproduce the problem! - This time on my own system where I'm properly equipped to debug it along with physical access to the hardware. Subsequent runs using the same settings successfully and consistently reproduced the issue - which means it can now be debugged.
And this is where things got even more interesting...
CPU Hazard in Zen4:
While I didn't intend to spoil it with the title, it needed to be in bold for anyone tl;dr'ing to this section. (especially any AMD engineers who might be reading!)
The code in question above that took 80 seconds to run was this:
const uint32_t* inA = ...;
uint32_t* outA = ...;
uint32_t* outB = outA + length;
uint64_t tmpA = 0;
int64_t tmpB = 0;
for (size_t c = 0; c < length; c++){
tmpA += inA[c];
tmpB += inA[c];
outA[c] = (uint32_t)tmpA;
outB[c] = (uint32_t)tmpB;
tmpA >>= 32;
tmpB >>= 32;
}
where (length = 5,033,164,800) for a total data size of about 60 GB. The loop itself is a very simple carry-propagation loop that was never parallelized.
80 seconds to execute 5 billion iterations at 5 GHz comes down to about 80 cycles per loop iteration. Anyone familiar with CPUs at this level will know that this loop should not take 80 cycles/iteration on any architecture under any circumstances. On Intel Skylake, this loop runs at around 5 cycles/iteration.
So what happened? Why does this loop suck so badly on Zen4*?
For (length = 5,033,164,800), the length factors into 226 * 3 * 52. This is a multiple of a large power-of-two. So the lower bits of the pointers outA and outB are the same - or what I like to call "super-alignment". What I suspect is that AMD's LSU (load-store unit) only uses the lower bits of pending accesses to determine memory aliasing. While it's hard to speculate on the exact mechanism, it's likely that outA and outB are being incorrectly aliased to each other causing their cache misses to serialize or some similar mechanism. Changing offsets to be a small offset from a large power-of-two doesn't fix it - which suggests that the false aliasing is spanning multiple loop iterations as would be expected given that these are all long cache misses all the way to ram.
Whatever the case is, AMD's poor handling of super-alignment plagues a lot of applications that naturally align to powers-of-two. This is the case for applications that rely heavily on FFTs (as is the case for y-cruncher). y-cruncher already goes to somewhat extreme lengths to avoid super-alignment hazards, but they still keep popping up on a regular basis - and only on AMD chips. Rarely is it this bad though. I'm not sure what Intel does that's so much better.
Thus the original "hangs" that were killing performance on Bergamo boiled down to two things that had to go bad simultaneously:
- Non-parallelized code being exposed by Amdahl's Law on 256-core Bergamo for a slowdown of at least 100x.
- That same non-parallelized code also hitting a hazard in Zen4 that slows it down by at least a factor of ~40x.
Thus a total slowdown of around 4000x**. Had either one not happened, the problem would've had a negligible effect on performance and gone unnoticed.
*While I haven't tested on anything other than Zen4 and Intel Skylake, it's likely that this hazard occurs on all AMD processors going all the way back to Bulldozer since I've seen similar behavior on AMD Piledriver.
**This 4000x estimate ignores the fact that the operation will become memory-bound if you both eliminated the hazard and perfectly parallelized it.
So what now?
This whole issue was discovered in November. And as of today (late December), it has been fixed for y-cruncher v0.8.4. It will not be backported to v0.8.3 due to the size of the changes. While working on this, I also discovered a bug in y-cruncher's carryout parallelism which was also difficult to fix and thus led me to push a patch to completely disable carryout parallelism in v0.8.3.
For this specific case, the fix involved two parts:
- Mitigate the super-alignment hazard by vectorizing the loop to AVX512.
- Parallelize the operation to fix the Amdahl's Law part.
While counter-intuitive, vectorizing the loop helps because it merges 16 groups of 4-byte accesses into 64-byte ones via AVX512. Since the problem has to due to memory serialization, doing 16x fewer accesses would cut the overhead of the hazard by 16x even if the # of bytes remained the same. AVX512 is required to vectorize this because mask register magic is needed to deal with the carry-propagation.
The more "natural" solution would've been to change the alignment of the data itself. But in this case, it would break the structure of the surrounding algorithm and cause lots of issues elsewhere. The loop isn't normally performance-critical enough to justify tearing apart the surrounding code.
As for the parallelism, this combined with the unrelated bug I found in v0.8.3 ultimately led me to completely redesign and expand y-cruncher's parallel carryout module. Carry-propagation is difficult to parallelize due to the inherent dependency chain that spans the entire dataset. A parallel prefix algorithm similar to the Kogge-Stone adder is needed to avoid the worst-case scenarios of pathological carryout. And to make matters worse, it's full of nasty corner cases which rarely happen with random input data that needs to be specifically tested and validated.
Overall, the changes were too large and dangerous to backport into v0.8.3. So the current release will need to live with this for a few more months.
Version 0.8.3 Released: (December 2, 2023) - permalink
And it's out now with the big improvements to swap mode SSDs and the new formulas for several constants! Thus this release wraps up the rewrite of v0.8.x as well as the year itself.
Looking forward to next year, I have a ton of things that I want to do. Whether I'll get to them is another story of course...
- Optimizations for Zen5. If the leaks about the 512-bit execution width are accurate, this could be a very juicy CPU.
- Replace the "11-BD1" binary for AMD Bulldozer with "12-BD2" for AMD Piledriver. This replaces FMA4 with FMA3 which makes it much easier to test and maintain.
- Fix some unparallelized code causing Amdahl's Law on modern large servers (specifically the 512-vcore Bergamos). More on this in a future post...
- Add the ability to checkpoint inside the radix conversion. This is very much needed as it has been a common failure point in the past.
- Increase y-cruncher's limit beyond 1015 digits. The current Pi record is 1014 digits, so it's getting close. This will require eliminating the "float-indexing limit".
- Modern SSDs have fast SLC caches. Can this be exploited? y-cruncher has the ability to exploit locality in hierarchical storage, but it has never been enabled due to difficulty in testing. Is it time to take another look?
For now, I don't expect to do any further Intel optimizations until one of the following happens:
- AVX512 returns to desktop. (unlikely)
- APX and AVX10 become available to desktop. (ETA 2025?)
- I manage to get a suitable Sapphire Rapids+ system for cheap.
If I happen to gain physical access to a suitable client chip (like if I'm building a rig for family/friends), I may be able to get the tuning parameters to build a new binary aimed at Alder Lake+ (without AVX512). But for the most part, the current "14-BDW" binary for Broadwell runs fine on modern non-AVX512 Intel chips. With AVX512 being mainstreamed by AMD, it's unlikely I will be personally buying anymore non-AVX512 x86 hardware unless it has something really interesting like APX+AVX10.
On the other hand, an ARM port is a possibility. Given that the entire project has never been compiled for anything outside of x86, I expect this to be a long and difficult journey that may be too much of a distraction from the main project goals. While I don't believe it is difficult to get y-cruncher to compile and run correctly for ARM, making it performant is another story.
The minimum performance target is to beat x86 emulation on Windows. From what I've heard, running y-cruncher with fast x86 emulation (no total store ordering) isn't terrible in performance - though sketchy from a correctness standpoint. (y-cruncher makes fairly extensive use of lockless programming, the fact that it runs at all without total store ordering surprises me.)
If I do decide to go down the ARM route, I intend to start with Windows since (I believe) all the system APIs are the same and is where I'm most comfortable. Linux may follow next, but ultimately the thing that matters is the Apple M1 since they seem to have the best ARM core right now.
The Windows on ARM devkits look promising (if they're ever in stock). Though I'm hesitant to pull the trigger on something I have no other use for.
Some Love for SSDs: (November 13, 2023) - permalink
Now that I've had time to flesh things out, this will be the long version of my recent tweet.
Over the years, I've avoided SSDs primarily due to their per-GB cost and limited write endurance. Workloads such as y-cruncher's swap mode can easily kill SSDs by using up their entire write endurance in a matter of weeks - shorter than some longer computations. For this reason alone, I've avoided them myself for this purpose and actively discouraged others as well. Consequently, y-cruncher's disk swapping frameworks remained optimized only for mechanical hard drives and were never tuned for SSDs.
While the situation hasn't changed much for consumer SSDs (they'll still die after a few weeks of sustained writes), StorageReview has shown that at least enterprise SSDs have improved enough to handle this kind of abuse. Thus it prompted me to take a new look at SSDs.
When Amazon Prime Day rolled around, I grabbed a set of high-end consumer SSDs (4 x Hynix P41 Platinum 2TB) and a PCIe bifurcation card to try a few things out. Obviously isn't the first time I've purchased SSDs, but it is the first time I've setup a clean testing environment to measure SSD performance.
And in short, the results were not good. While bandwidth scaling from 1 -> 4 SSDs remained linear, the achieved bandwidth per SSD fell short of what standard synthetic benchmarks (such as CrystalDiskMark) could achieve. This actually caught me by surprise since I stupidly thought that sequential access would easily blow through a hard drive optimized framework. Apparently not...
|
||||
Core i9 7900X with 4 x SK Hynix Platinum P41. Connectivity is PCIe3x16 (theoretical max bandwidth of 16 GB/s). |
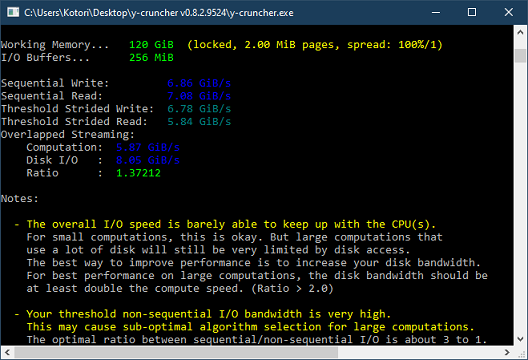
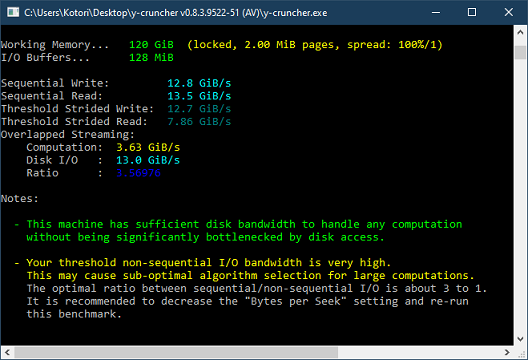
Testing each SSD in isolation, CrystalDiskMark was able to achieve 3.5 GB/s and 6.5 GB/s on PCIe 3.0 and PCIe 4.0 respectively. y-cruncher's Disk Raid 0 framework had trouble reaching just 2 GB/s. This is embarrassing to say the least since this has been a problem for years. In retrospect, this post back in 2019 probably tried to alert me to this which I overlooked. (I suspect a language barrier, since the author is probably from the Japanese site with the same name.)
So what was the problem? Why does y-cruncher suck so much on SSDs?
- Queue Depth: SSDs need a high queue depth to achieve maximum bandwidth. This requires parallel I/O. y-cruncher has never supported parallel I/O since it's bad for hard drives due to it causing disk seeks. (Parallel I/O is only beneficial on hard drives for small accesses when NCQ is supported. But y-cruncher does mostly large sequential accesses.)
- CPU Bottleneck: y-cruncher's disk (raid) management requires CPU computation to perform sector alignment and raid interleaving. This CPU work is done on the same thread as the disk I/O DMA calls - thus are serialized with the disk I/O. On hard drives, the CPU work is negligible since the disk I/O is so slow. But modern NVMe SSDs are so fast that the I/O no longer dominates the run-time compared to the CPU work. Thus on SSDs, a lot of the time is wasted waiting for CPU work rather than performing disk I/O.
So y-cruncher's Disk Raid 0 framework is getting redesigned to fix these issues:
- Disk I/O can now be Parallelized: Concurrent I/O requests are no longer serialized by the framework. Furthermore, large requests are now broken up and issued in parallel to the underlying devices. (I'm surprised the hardware doesn't already do this.)
- Software Native Command Queuing: Disk I/O now goes through an out-of-order scheduler with multiple worker threads. So it can parallelize the CPU work with disk I/O, re-order requests to break dependencies, and intentionally schedule reads in parallel with writes to utilize bidirectional* connections (such as NVMe PCIe).
Obviously, these optimizations are actively detrimental to hard drives. So the redesigned framework will have options to load optimized settings for hard drives vs. SSDs.
The results so far are very good on Windows as I've been able to reach about 90% of CrystalDiskMark's raw per-drive sequential performance. Given that swap-mode computations are so heavily I/O bound, I expect this to translate to massive speedups for such computations on SSD - larger than v0.7.10 -> v0.8.1 speedup of in-ram computations.
These SSD improvements along with the new formulas for several constants are enough for a release. So barring any major issues, expect v0.8.3 in a few weeks.
*Parallelization of reads with writes was something that Emma Haruka Iwao (from the Pi world records) suggested years ago since the Google Cloud network stack has separate ingress and egress links that do not share bandwidth. However, utilizing this would have required major redesigns in y-cruncher's swap mode computation stack. This finally happened as part of the revamp of v0.8.x where the new swap-mode FFT in v0.8.2 was designed to support issuing concurrent I/O operations to the storage framework (including reads with writes). However, that alone is not sufficient since all the disk I/O frameworks still serialized everything. Now, v0.8.3 fixes this last part by allowing the disk I/O framework to forward those parallel I/O requests to the underlying storage itself. Preliminary tests show that under very specific and favorable cirumstances, y-cruncher v0.8.3 is able to exceed the maximum bandwidth of PCIe by parallelizing reads with writes. But it remains to be seen if this translates to actual computations.
New Formulas by Jorge Zuniga: (October 25, 2023) - permalink
Jorge Zuniga, building off the work of Jesus Guillera and other mathematicians, has found a large number of very fast formulas for Zeta(3), Catalan's Constant, Lemniscate and others. As a result, the fastest formulas for these constants has almost been completely wiped and overhauled with new ones!
| Old Fastest Formulas | New Fastest Formulas | Speedup | |
| Zeta(3) - Apery's Constant | Wedeniwski (1998) Amdeberhan-Zeilberger (1997) |
Zuniga (2023-vi) Zuniga (2023-v) |
34% 25% |
| Catalan's Constant | Pilehrood (2010-short) Guillera (2019) |
Pilehrood (2010-short) Zuniga (2023) |
- 23% |
| Lemniscate Constant | AGM Gauss' ArcSinlemn |
Zuniga (2023-viii) Zuniga (2023-vii) |
> 20% 2.8x |
These new formulas can be found on the formulas page and will be added natively to y-cruncher in v0.8.3 where they will replace all the old and outdated formulas.
In addition to these main constants, there are also improvements to some of the constants which will only be available via custom formulas:
- Zeta(5) has a faster 2nd formula. (wasn't discovered by Zuniga, but he dug it out from an existing publication and showed that it was fast)
- Gamma(1/3) has a new fastest formula.
Of course, these aren't the only formulas that were found. The full list of them is here and are available as custom formulas:
- Zeta(3) - Zuniga (2023-i)
- Zeta(3) - Zuniga (2023-ii)
- Zeta(3) - Zuniga (2023-iii)
- Zeta(3) - Zuniga (2023-iv)
- Zeta(3) - Zuniga (2023-v)
- Zeta(3) - Zuniga (2023-vi)
- Catalan - Zuniga (2023)
- Lemniscate - Zuniga (2023-o)
- Lemniscate - Zuniga (2023-i)
- Lemniscate - Zuniga (2023-ii)
- Lemniscate - Zuniga (2023-iii)
- Lemniscate - Zuniga (2023-iii) (G2)
- Lemniscate - Zuniga (2023-iv)
- Lemniscate - Zuniga (2023-v)
- Lemniscate - Zuniga (2023-vi)
- Lemniscate - Zuniga (2023-vi) (G2)
- Lemniscate - Zuniga (2023-vii)
- Lemniscate - Zuniga (2023-viii)
- Gamma(1/3) - Zuniga (2023)
- Lemniscate - Guillera (2023)
- Zeta(5) - Y.Zhao
- Dirichlet L(-3,2) - Guillera (2023)
Meanwhile, Jurjen N.E. Bos managed to dig up a hypergeometric series for epi. While there has been some demand to compute this, it wasn't possible with y-cruncher due to the lack of a non-integer power function. That finally changes now! However, we don't have a second formula yet for verification purposes. If you are aware of one that can be implemented using y-cruncher's custom formula feature, please let me know!
This isn't the first time that major mathematical improvements were brought to y-cruncher (the first time was 5 years ago). But this is the first time that the math community has actively searched out formulas for y-cruncher using my criteria for measuring the speed of a hypergeometric series.
There's more coming in v0.8.3 mostly involving improvements to SSDs for swap mode. But more on that later as it's still a work-in-progress.
Version 0.8.2 Released: (September 4, 2023) - permalink
Part 2 of the revamp is now complete! While part 1 (version v0.8.1) rewrote the large multiplication for in-memory computations, this release finishes the job by extended it to swap computations as well.
Because this release completely replaces the old disk multiplication, it is strongly recommended to test things at scale if you plan on doing any large compuations (such as a Pi record). I have not personally tested anything above 1 trillion digits.
So with this release, the revamp is effectively complete:
- The HNT, N32, N64, VST, and C17 algorithms are now obsolete. All of them except VST have been disabled in this release.
- The replacements are N63 and VT3, which are rewrites of the N64 and VST respectively using the new FFT design.
While I had plans to also rewrite the floating-point FFTs, those are being shelved for later as the cost/benefit doesn't meet the bar against other higher priority tasks.
So as of this release (v0.8.2), y-cruncher peaks at 729,000 lines of code. Now the cleanup begins. The 5 algorithms (all except VST are already disabled in v0.8.2) will be removed from the codebase for a reduction of at least 240,000 lines of code. Meanwhile, the N63 and VT3 algorithms have added 133,000 lines of code.
Thus the net change of the entire revamp will be a reduction of roughly 100,000 lines of code with a total of just under 400,000 lines touched - which is close to what I had initially predicted.
Part 3 of the revamp is just cleanup and will involve removing the code for the 5 obsolete algorithms. Since this involves a removal of features with nothing added in return, it will not get its own release and will simply be rolled into the next set of improvements.
The VST algorithm, despite being popular for stress-testing, will not be spared as it has dependencies on much of the 240,000 lines that will be removed. So it will be removed in v0.8.3 whenever that might be. The overclocking community has already shown that VT3 is the stronger stress-test so this should not be a huge loss.
As for performance changes, don't expect the same massive speedups for swap mode that v0.8.1 brought to in-memory computations. Swap mode computations were (and still are) disk-bound. So the computational improvements which gave v0.8.1 the large speedups will not translate proportionally to computations on disk.
Material improvements to swap mode are slated for the future. While this release lays down much of the groundwork for future improvements, a lot more work and research is needed to get there.
What's next?
The cleanup and removal of the old algorithms is already done on the main development branch. So with the project at a good stopping point, I'll be taking a break from any major developments. I'm also not in the mood to do anything since I recently lost a very close member of the family.
Regardless, I intend to continue doing new binaries for whatever new and interesting processors I can get my hands on. Just don't expect any big changes (like the v0.8.1 improvements) for a while.
In memory of my uncle Robbie whom I was extremely close to and was effectively my 3rd parent growing up. Rest in peace. You'll be missed dearly. I will drive your Tesla someday, though it might be a while.
Version 0.8.1 Released: (July 11, 2023) - permalink
And it's finally here! Part one of the revamp is now complete. This release brings forward the newly rewritten algorithms which will have the most performance impact for in-memory computations.
Here are some benchmarks showing the improvements brought by v0.8.1 and AVX512. Because of the large performance swings, HWBOT integration will be withheld until the HWBOT community decides what to do.
|
|
||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||
Last year when I did the Zen 4 optimizations, I was disappointed (but not surprised) that I was only able to gain 1-2% speedup with AVX512. In fact, this was so embarrassingly bad that I couldn't publish any numbers. Sure, Zen 4's AVX512 is "double-pumped" and doesn't have wider units. But there's a lot more to AVX512 than just the 512-bit width.
In reality, I was able to achieve around 10% speedup for AVX512 on Zen 4 - but only within cache. Upon scaling it up, it was completely wiped out by the memory inefficiencies in the old algorithm. And it certainly didn't help that Zen 4 set a new record for insufficient memory bandwidth.
This memory bottleneck I suspect is the primary reason why the overall benefit of AVX512 remains higher on Intel than AMD even in v0.8.1. y-cruncher has been memory-bound on every high-end chip since 2017 with AMD faring worse due to having twice as many cores and lower memory speeds. While it's also tempting to blame Zen 4's "double-pumped" AVX512 as part of the problem, in reality it isn't much worse than Intel chips that lack the second 512-bit FMA.
Memory bandwidth as a whole has been a problem that has gone completely out of control. Since 2015, computational power has increased by more than 5x while memory bandwidth has barely improved by 50%. Needless to say, this trend is completely unsustainable at least for this field of high performance computing.
Stress Testing:
Testing and validation of v0.8.1 was done on 8 computers which were long believed to be stable (most aren't even overclocked). All 8 of these machines held against older versions of y-cruncher during past releases. But for this release, 2 of them were found to be unstable. Neither were overclocked and were completely within spec.
Neither machine could be fixed by downclocking or overvolting. One of them (an Intel laptop) had to be retired. The other (a custom-built AMD desktop) was eventually stabilized by changing the motherboard. (Yes, this was a huge headache and a massive distraction from the software development.)
What does this mean for stress-testing? While it's tempting to conclude that v0.8.1 is more stressful than older versions, this sample size of 8 really isn't enough. So I'll leave it to the rest of the overclocking community to decide. The specific stress-test you want to run is called "VT3" which is the newly rewritten version of the "VST" test that everyone seems to love. Likewise, any large in-memory computation will be running the new code.
The Hybrid NTT Algorithm:
As promised in the previous announcement, y-cruncher's good old Hybrid NTT algorithm has now been published here. Despite its importance to y-cruncher's early days, it is not as conceptually spectacular as one would assume by modern (adult) standards. But as a kid when I first wrote it, it was amazing.
Anyways, I hope everyone enjoys this new version. As mentioned, this is just part one of the ongoing rewrite of the internal algorithms. While there's still a lot of work to do (including optimizations), development will now shift to swap mode. So in the short term, I don't expect any more performance swings beyond compiler changes and new optimizations for new processors.
Upcoming Changes for v0.8.x: (June 7, 2023) - permalink
In an effort to clean up and modernize the project, most of the large multiply algorithms are getting either refreshed or removed. Algorithms that are useful on modern processors are getting redesigned and rewritten from scratch while the rest will be completely removed from the codebase.
The implication of this will be performance gains on newer processors and regressions on older processors.
If this sounds big, it is. More than 400,000 lines of code will be touched. Work actually began more than 3 years ago, but very little progress was made until this year where I'm on garden leave and therefore not working.
As of today, enough has been done to get some preliminary in-memory benchmarks:
| Processor | Architecture | Clock Speeds | Binary | ISA | Pi computation Speedup vs. v0.7.10 | |
| Core i7 920 | Intel Nehalem | 2008 | 3.5 GHz + 3 x 1333 MT/s | 08-NHM ~ Ushio | x64 SSE4.1 | -27% |
| Core i7 3630QM | Intel Ivy Bridge | 2012 | stock + 2 x 1600 MT/s | 11-SNB ~ Hina | x64 AVX | -10% |
| FX-8350 | AMD Piledriver | 2012 | stock + 2 x 1600 MT/s | 11-BD1 ~ Miyu | x64 FMA4 | -1% |
| Core i7 5960X | Intel Haswell | 2013 | 4.0 GHz + 4 x 2400 MT/s | 13-HSW ~ Airi | x64 AVX2 | 3 - 4% |
| Core i7 6820HK | Intel Skylake | 2015 | stock + 2 x 2133 MT/s | 14-BDW ~ Kurumi | x64 AVX2 + ADX | 4 - 7% |
| Ryzen 7 1800X | AMD Zen 1 | 2017 | stock + 2 x 2866 MT/s | 17-ZN1 ~ Yukina | x64 AVX2 + ADX | ~1% |
| Core i9 7900X | Intel Skylake X | 2017 | 3.6 GHz (AVX512) + 4 x 3000 MT/s | 17-SKX ~ Kotori | x64 AVX512-DQ | 6 - 9% |
| Core i9 7940X | 3.6 GHz (AVX512) + 4 x 3466 MT/s | 10 - 13% | ||||
| Ryzen 9 3950X | AMD Zen 2 | 2019 | stock + 2 x 3000 MT/s | 19-ZN2 ~ Kagari | x64 AVX2 + ADX | 13 - 14% |
| Core i3 8121U | Intel Cannon Lake | 2018 | stock + 2 x 2400 MT/s | 18-CNL ~ Shinoa | x64 AVX512-VBMI | 16 - 17% |
| Core i7 1165G7 | Intel Tiger Lake | 2020 | stock + 2 x 2666 MT/s | 12 - 22% | ||
| Core i7 11800H | stock + 2 x 3200 MT/s | 23 - 27% | ||||
| Ryzen 9 7950X | AMD Zen 4 | 2022 | stock + 2 x 4400 MT/s | 22-ZN4 ~ Kizuna | x64 AVX512-GFNI | 23 - 31% |
The loss of performance for the oldest processors is primarily due to the removal of the Hybrid NTT. Yes, the Hybrid NTT that started the entire y-cruncher project is now gone. While it was the fastest thing in 2008, it unfortunately did not age very well. Stay tuned for a future blog about the algorithm. It will no longer be a secret.
Overall, there is still a lot of work to do. For example, swap-mode is still using the old implementations and will need to be revamped as well. But since the new code has reached or exceeded performance parity for the chips I care about, this is a good stopping point for v0.8.1 pending testing and validation.
Nevertheless, the benchmarks above are not final and are subject to change. Specifically, there are unresolved toolchain issues where Intel is removing their old compiler while its replacement is still significantly worse. And it's unclear whether it can be fixed before it is no longer possible to keep using their old compiler.
A big unknown is how stress-testing will be affected. Despite not being designed for this purpose, y-cruncher's stress-test is notorious for its ability to expose memory instabilities that other (even dedicated) memory testing applications cannot. In other words, it is one of the best memory testers out there. But with so much stuff being rewritten, there's no telling how this will change. Nevertheless, it doesn't make a whole lot of sense to keep around hundreds of thousands of lines of old code if turns out to be the better stress test.
So yeah... Out with the old and in with the new. Expect to see Zen 4 gaining up to 20% speedup with AVX512 vs. just AVX2 - no wider execution units needed.
The Need for Speed!: (April 19, 2023) - permalink
Jordan Ranous from StorageReview has just flexed a system that matched Google's 100 trillion digit world record in just 59 days. You can read more about it here:
- https://www.storagereview.com/review/storagereview-calculated-100-trillion-digits-of-pi-in-54-days-besting-google-cloud
- https://news.solidigm.com/en-WW/225029-solidigm-helps-break-world-record-pi-calculation
- Validation File: Download
I'm not sure if Google's record used SSDs or hard drives, but if the latter, this would be the first large computation done entirely on SSDs.
It's probably safe to say that since StorageReview is able to match the world record in a fraction of the time, they are more than capable of beating it. So everyone else better watch out!
Intel Optimizations (or lack of): (April 17, 2023) - permalink
I've been asked a number of times about why I haven't done any optimizations for recent Intel processors. The latest Intel processor which y-cruncher has optimizations for is Tiger Lake which is 2 generations behind the latest (Raptor Lake). And because Raptor Lake lacks AVX512, it can only run a binary going all the way back to Skylake client (circa 2015).
There are a number of reasons for this:
- Removal of AVX512 starting from Alder Lake.
- Heterogeneous computing (splitting of P and E-cores) is difficult to optimize for.
- Memory bandwidth remains the biggest bottleneck.
Removing AVX512 is a huge step back in more ways than just the instruction width. It also removes all the other (non-width) functionality exclusive to AVX512 such as masking, all-to-all permutes, and increased register count. From a developer perspective, this very discouraging since most of the algorithms I've been working on since 2016 have been heavily influenced by (if not outright designed for) AVX512.
The lack of AVX512 is likely why Tiger Lake and Rocket Lake outperform Alder Lake in single-threaded benchmarks where memory bandwidth and core count are not a factor.
The split of P and E cores is quite frankly a nightmare to optimize for at all levels:
- At the lowest level, different instruction sequences run differently on different cores types, thus no single sequence is optimal on both.
- At the mid level, the different core types have different cache layouts, thus requiring different cache blocking mechanisms depending on what core you're running on. In most cases, cache blocking parameters for a task cannot be changed while it is running. Thus there is no way to adapt should the thread be moved to a different core type - and that's assuming there is a way for the thread to even know it was moved.
- And at the highest level, efficient parallelization is almost hopeless as you can no longer assume that tasks of similar size will finish in a similar amount of time. Any attempts to steer certain threads to certain core types (say to prevent a thread running code that's optimized for a specific core type from moving to the wrong core) will inevitably lead to complications with load balancing.
This is not to say it's impossible to optimize for heterogeneous computing, but it is not a direction that I would like to move y-cruncher towards.
Obviously, Intel had their reasons to do this. Client processors are not generally used for HPC, they are used for desktop applications - like gaming. I suspect that Intel went in this direction in an attempt to remain competitive with AMD once it became apparent that the only way they could match AMD in both single-threaded and multi-threaded performance was to build a chip that had P-cores specifically for single-threaded tasks and E-cores for multi-threaded ones.
That said, AMD also seems to be moving in the direction of heterogeneous computing with the 2-CCD Zen4 3D V-Cache processors. This is also something that cannot be easily optimized for.
What about the server chips?
Server chips for both Intel and AMD remain sane for now. And I hope they stay that way since this is where the majority of HPC lives. And while there's room here, (in particular: Intel's Sapphire Rapids and AMD's Genoa-X with 3D V-Cache), they all remain far beyond my personal budget. So barring a sponsor or a donation, I'm unlikely to target these systems any time soon.
In the end, none of this matters a whole lot because of memory bandwidth. With or without AVX512, and with or without optimized code for each core type, memory bandwidth holds everything back. And this applies to both Intel and AMD. Thus from a developer perspective, it makes zero sense to go to hell and back to deal with heterogeneous computing when it won't matter much anyway. Furthermore, this heterogeneous computing revolution is different from the multi-core revolution of 2 decades ago in that parallel computing brought unbounded performance gains whereas heterogeneous computing can only squeeze out a (small) constant factor of speedup.
So rather than figuring out heterogeneous chips, most of the work has been research on memory bandwidth. y-cruncher's existing algorithms already have their space-time-tradoff sliders completely maxed out in the direction of reducing memory/bandwith at the cost of additional computation. So new stuff will be needed.
One of the biggest weaknesses in y-cruncher is its inability to fully utilize modern caches which are large, shared, and deeply hierarchical. So on paper, AMD shows the most potential for future improvement here because that massive 3D V-Cache is very much underutilized.