News (2018)
Back To:
Computation of Pi using a Custom Formula
|
Custom Formulas: (October 28, 2018) - permalink
For those of you who have been paying attention to the record lists, you'll have noticed some new constants which y-cruncher has not supported before. Long story short, I've been experimenting with a custom formula feature similar to that of PiFast's User Constants. And at this point, it's in a good enough shape to announce.
y-cruncher's focus has always been to focus on a small number of popular constants and take them to the extreme. But it's been on the back of mind for years to add some sort of formula feature to allow people to use y-cruncher's capabilities to compute other things as well. I'm glad to say that this will finally be coming in v0.7.7.
The new formula feature will allow users to input arbitrary (finite sized) formulas with functions such as:
- Addition, subtraction, multiplication, division, and integer power.
- Square root and inverse square root.
- AGM, Log of integer, ArcCoth, ArcSinlemn
- Hypergeometric series (with restrictions)
- All the existing constants.
These encompass nearly all of y-cruncher's internal functionality. The AGM and large number square root are new to y-cruncher v0.7.7 and didn't exist before. This set of functions is not final and will probably grow a bit more before v0.7.7 is released.
A list of formulas can be found here: https://github.com/Mysticial/y-cruncher-Formulas/tree/master/Formulas
This custom formula feature may seem like it's coming out of nowhere. But it's been in the making for years. There's a long list of reasons why it took so long:
- Technical Debt: y-cruncher's mathematical code was never modularized enough to allow such a feature. This took around 2 years of incremental cleanups and refactorings to finally achieve.
- y-cruncher's resource management is very restrictive and is not easily generalizable to arbitrary formulas. For example y-cruncher calculates how much memory/storage is needed for a computation. This is difficult enough for hard-coded formulas - let alone arbitrary ones. This was eventually achieved through incremental conversion of the code to formal programming methods.
- Much of y-cruncher's bignum code did not properly handle corner cases. For example, zero, subtraction sign-flips, and destructive cancellation either never happen or are easily avoided in computations of Pi and other natural constants. But they can easily happen with user-input formulas.
- y-cruncher never had a way to express and serialize formulas. This became possible when the configuration files were implemented.
- Characterizing and sanitizing user-input for hypergeometric series polynomials involved an area of math for which I had no expertise in.
The custom formula feature is not yet complete. Given the scale of such a feature, it will require more than the usual amount of testing. So it's still months away.
Catalan's Constant is No Longer a Slow Constant: (August 23, 2018) - permalink
In what is probably the first major mathematical improvement since the start of the y-cruncher project, there are 3 new formulas for Catalan's Constant.
I was recently made aware of a publication by F. M. S. Lima which directly and indirectly led to 3 new formulas for Catalan's Constant which are faster than the Lupas formula which had been the fastest for more than a decade.
| Name | Formula | Speedup vs. Lupas |
| Guillera | 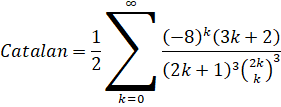 |
1.7x |
| Pilehrood (short) | 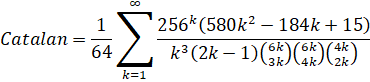 |
3.8x |
| Pilehrood (long) | 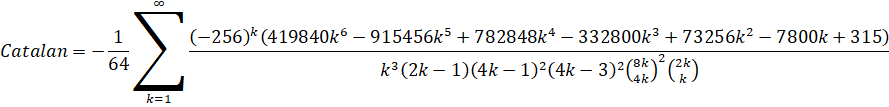 |
2.5x |
All 3 formulas have been implemented for y-cruncher v0.7.7. But the timing of this with respect to y-cruncher's release cycle (having just released v0.7.6), means it will be months before these formulas see the light of day for y-cruncher. But at the very least, we know that they exist and that they work. All 3 implementations have been tested to 1 billion digits. (which didn't take very long)
Catalan's Constant has historically been one of the slowest mainstream constants to compute - second only to the Euler-Mascheroni Constant. But thanks to these formulas, Catalan's Constant is now almost as fast as Zeta(3).
As only two independent algorithms are needed to establish records, the existing formulas by Lupas and Huvent (as well as Guillera's formula) are now effectively out-of-date. But there are no immediate plans to remove any of the outdated formulas.
Mathematics evolves at a much slower pace than computer hardware. So it is easy to forget that math remains one of the most important parts of high precision computations. Without such formulas and algorithms, large computations would be impossible. So we must never stop thanking the generations of mathemeticians, both past and present, that have made such projects possible.
While we wait for v0.7.7, two new articles have been added to the algorithms page:
Version 0.7.6: (August 11, 2018) - permalink
A new version is out. This release is mostly a dump of bug fixes, internal refactorings, and secondary features. So not a whole lot on the outside.
The only major feature is the "18-CNL" binary for Cannon Lake processors. Due to the lack of suitable hardware from the delays in Intel's 10nm process, it will probably remain untuned and not fully tested until at least 2020. The Core i3 8121U systems that currently exist are too difficult to obtain and are likely "too small" to do the tuning that y-cruncher needs.
Spectre Attack via AVX Clock Speed Throttle: (August 7, 2018) - permalink
Somewhat off-topic, but not entirely unrelated since AVX is a common theme here.
Apparently, the AVX clock speed throttle present in Intel processors is yet another Spectre attack vector. This is something that I've been thinking about on-and-off since January, but the conceptual breakthrough didn't happen until June.
Unbeknownst to me, NetSpectre a closely related exploit, was already in the workings and was publicized in July while my thread with Intel security was still ongoing.
In the end, my communications with Intel were less productive than I had expected. So I'm now publishing the blog describing the attack. (Related Tweet)
The contents of the blog are now out-of-date in the context of NetSpectre. But I'll leave it as is - the way I intended to publish it back in June.
Feel free to reach out to me about this topic on Twitter or something. While I'm not a researcher in this area, I do have some other ideas for Spectre attacks and enhancements which I'm not really interested in pursuing. So it would be neat if someone else can turn them into working exploits.
AVX512 Scalability - One Year In: (July 2, 2018) - permalink
When AVX512 (for consumer hardware) launched a year ago with Skylake X, few applications supported it. y-cruncher was one of those few, but the performance was very disappointing due to all sorts of hardware issues and unexpected performance bottlenecks.
Over the past year, work was done to target those bottlenecks. And while they failed to eliminate them, they still improved performance by a lot. So now that there's been enough time to properly optimize and tune for AVX512, we can finally do a fair evaluation of this instruction set for bignum crunching.
The table below shows scalability across two dimensions: instruction set (AVX2 -> AVX512) and parallelism. This processor has 10 cores hyperthreaded to 20 threads. The clock speed is normalized to 3.6 GHz for all workloads. This is admittedly unrealistic since AVX512 will usually run at a lower frequency. But it does provide a perfect clock-for-clock comparison between AVX2 and AVX512.
1 Billion Digits of Pi - (Times in Seconds) Core i9 7900X @ 3.6 GHz - 4 x DDR4 @ 3000 MT/s |
||||||
| y-cruncher v0.7.3 (July 2017) | y-cruncher v0.7.6 (ETA 2018) | |||||
| 14-BDW (AVX2) | 17-SKX (AVX512) | Speedup | 14-BDW (AVX2) | 17-SKX (AVX512) | Speedup | |
| 1 thread | 473.317 | 331.888 | 1.43 x | 439.967 | 272.042 | 1.62 x |
| 20 threads | 48.658 | 39.862 | 1.22 x | 41.833 | 30.645 | 1.37 x |
| Speedup | 9.73 x | 8.33 x | 10.50 x | 8.88 x | ||
The single-threaded benchmarks show the raw speed of AVX2 vs. AVX512. While everything got faster from v0.7.3 to v0.7.6, the AVX512 improved more. This is because v0.7.6 has all the new optimizations that can only be done with real AVX512 hardware. In contrast, v0.7.3 was released only 2 weeks after Skylake X was launched. Much of the AVX512 in v0.7.3 was written years ago using only emulators and before the hardware ever existed in silicon.
The multi-threaded runs show smaller speedups from AVX2 to AVX512. This is due to memory bandwidth becoming a factor. Even with 4 channels of high-clocked memory, Skylake X with more than a few cores does not have enough memory bandwidth to feed all the cores. Many of the optimizations between v0.7.3 and v0.7.6 were targeted at alleviating this bottleneck.
So as of 2018, the raw AVX2 -> AVX512 speedup is 62% on Skylake X with dual 512-bit FMAs. Given the amount of code that remains unvectorized, 62% is reasonable due to Amdahl's Law. Furthermore, AVX512 only doubles up the floating-point capability. Many integer operations fall well short of that.
But once everything else is factored in (AVX512 clock speed throttle and memory bandwidth with multi-threading), the real speedup of AVX512 on a large Skylake X processor with a lot of cores dwindles to around 20 - 30%. Disappointing? Yes. But not unsurprising for new technology. Perhaps things will be better when DDR5 becomes a thing.
Cannon Lake?
Maybe it's too early to start talking about Cannon Lake since it will still be a long time before they hit the market in volume.
250 Million Digits of Pi - (Times in Seconds) Core i3-8121U @ unknown fixed clock speed* |
|||
| y-cruncher v0.7.6 (ETA 2018) | |||
| 14-BDW (AVX2) | 17-SKX (AVX512-DQ) | 18-CNL (AVX512-VBMI) | |
| 1 thread | 100.057 | 87.840 | 66.510 |
The Core i3-8121U is a 10nm Cannon Lake processor with only one 512-bit FMA. Having only one FMA severely limits the performance of the baseline AVX512. But the new binary seems to care less. It's way too early to draw any conclusions yet.
*Credit to Jzw for testing this.
Pi Day and "houkouonchi": (March 14, 2018) - permalink
For those who have been following the Pi computation world records, you'll know that "houkouonchi" is obviously a pseudonym. Back in 2014 when he set the Pi world record with 13.3 trillion digits, he asked me not to reveal his real name. His reason: He didn't want to be bothered by people contacting him through his facebook and personal email.
However, houkouonchi sadly passed away in 2015.
Being an internet contact, I didn't find out about it for almost a year. Furthermore, I had no contact information for his family members.
For the past 2 years, I've been torn on whether or not to reveal his real name. On one hand, he asked me not reveal his name. But on the other hand, I felt a strong desire to put his name on his world record. Without any contact information, I've been unable to reach out to his family. And nobody is watching his email as my messages have remained unanswered.
In the end, I decided that his original reason for being anonymous is no longer applicable. Therefore I will now put a name to the record of 13.3 trillion digits.
His name is Sandon Van Ness. Rest in peace my friend.
Page Table Isolation and Large Pages: (January 7, 2018) - permalink
If you follow tech news, you should be well aware of the Meltdown and Spectre side-channel attacks that affect nearly all processors with speculative execution. Furthermore, the patches come with performance penalties that range anywhere from negligible to a ridiculous 50% depending on the application and hardware.
Is y-cruncher affected? Yes. But it may be avoidable under certain circumstances.
Hardware:
- Core i7 4770K (Haswell) @ 4.0 GHz (4 cores/8 threads)
- 32 GB DDR3 @ 2133 MT/s
- Asus Z87-Plus
- Windows 10 Anniversary Update
The following table compares performance with and without KPTI for Meltdown. Unfortunately, no BIOS/microcode update for the Spectre patch was available to test. Given the age of the system, it seems unlikely that the manufacturer will provide such an update.
| 1 billion digits of Pi | y-cruncher v0.7.4 | |
| Normal Pages (4 KB) | Large Pages (2 MB) | |
| No Patches | 107.448 | 106.803 |
| Kernel Page Table Isolation (KPTI) | 110.418 | 106.388 |
Notes:
- All times are in seconds.
- Each benchmark was done multiple times to ensure consistency and the fastest time was chosen. Run-to-run variation is on the order of +/- 0.5%.
- When PTI was enabled, it was enabled with the PCID (Process-Context Identifiers) optimization.
y-cruncher spends very little time in the kernel. So based on that, one would expect the effect of KPTI to be negligible. However, there are a lot of small system calls from all the multi-threading related constructs. (mutexes, condition variables, signals, etc...)
In the end, we see a 3% performance impact when using normal (4 KB) pages. But when switching to large (2 MB) pages, that penalty disappears.
A possible explanation for this is that each system call that goes into kernel mode will cause a TLB flush upon its return. So even if the system call is short, it leads to a flood of TLB misses as the computation resumes and has to re-populate the TLB. Since y-cruncher has a massive memory footprint, there will be a lot of pages to re-populate. With large pages, there are far fewer of them - thereby drastically reducing the performance penalty. Though this explanation has issues since PCID should (theoretically) be eliminating the TLB flushes as far as I understand (which I admit I don't).
Regardless of the exact reason for why large pages help so much, let's not get too excited. This is just a single benchmark on a single platform. Things may look different on other systems. Furthermore, there are requirements to enable large pages - some of which may be inconvenient.
Those interested in testing out large pages for y-cruncher can refer to the memory allocation guide.
Looking forward, the current development version of v0.7.5 is showing significantly less penalty from KPTI:
| 1 billion digits of Pi | y-cruncher v0.7.5 (trunk) | |
| Normal Pages (4 KB) | Large Pages (2 MB) | |
| No Patches | 104.337 | 102.995 |
| Kernel Page Table Isolation (KPTI) | 104.581 | 103.142 |
It's unclear why this is the case. But it could be a side-effect of the new bandwidth optimizations.
Version v0.7.5 is currently not ready for release. However, it is in feature freeze.
Spectre Mitigations:
So far, I have yet to test the impact of the Spectre mitigations.
- Retpoline should be irrelevant as long as compilers make it optional. So that leaves its usage in the kernel. But y-cruncher spends so little time in the kernel anyway that there should be little effect of any retpoline overhead in the kernel itself.
- Microcode updates for branch target injection are still unclear. If we assume worst case in that they disable branch target prediction, y-cruncher is expected to be affected, but only minimally so. While y-cruncher makes fairly heavy use of virtual calls, they are never used in any place that is super performance critical.