Google Cloud Topples the Pi Record
By Alexander J. Yee (@Mysticial)
(Last updated: March 14, 2019)
March 14, 2019:
Shortcuts:
Happy Pi Day! This time, we are announcing a new world record of 31.4 trillion digits of Pi!
From September to January, Emma Haruka Iwao of Google (@Yuryu) ran a computation of Pi to 31.4 trillion digits - surpassing Peter Trueb's 2016 computation of 22.4 trillion.
The exact number of digits that was computed is 31,415,926,535,897 decimal digits and 26,090,362,246,629 hexadecimal digits.
Last Decimal Digits:
6394399712 5311093276 9814355656 1840037499 3573460992 : 31,415,926,535,850
1433955296 8972122477 1577728930 8427323262 4739940
Last Hexadecimal Digits:
71467b597c efe8be6acc a3301327c9 34f72265a5 d745a239ed : 26,090,362,246,600
cc238665e9 17c5727284 e08bdde8e
More information can be found on the official Google blogs:
|
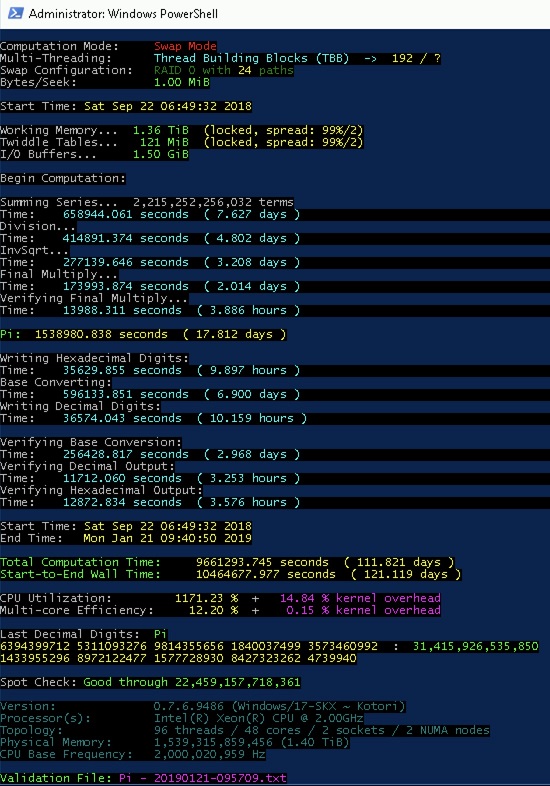
The computation used the Chudnovsky formula and took 121 days beginning on September 22, 2018 and ending on January 21, 2019. Verification was done twice using Bellard's 7-term BBP and the original 4-term BBP formulas.
These were run in December and took 20 and 28 hours respectively. This method of computation and verification has remained the same for the previous 6 times the Pi record has been broken. All advances have been entirely in software and hardware.
The computation was done on the following Google Cloud nodes:
- Computation: 1 x n1-megamem-96 (96 vCPU, 1.4TB) with 30TB of SSD
- Storage: 24 x n1-standard-16 (16 vCPU, 60GB) with 10TB of SSD
The primary node for the computation ran Windows Server 2016 and has a pair of Skylake Xeon processors with AVX512. The exact specs of the hardware are undisclosed. 24 smaller nodes were used for network attached storage. These combined for a total of about 240 TB of storage.
The verification was done on my own custom-built PC with:
- Intel Core i9 7900X @ 3.5 GHz (overclocked all-core AVX512)
- 128 GB memory @ 3600 MT/s (overclocked)
- GeForce GTX 1050 Ti
- 500 GB SSD + 2 TB 7200 RPM HD
- Windows 10 Build 16299
Both the computation and verification runs were done using y-cruncher v0.7.6.
The validation file for this computation can be found here. But note that the reported hardware configuration isn't entirely accurate due the information being hidden/faked by the Google Cloud virtual machine environment.
Miscellaneous Facts and Statistics:
- This is the first Pi record done on a commercial cloud service. Thus proving that modern cloud services can feasibly be used for this type of high performance computing.
- This is the first Pi record done using solid state drives (SSD). Historically, SSDs were never used because they are expensive and had limited write endurance. This is the first such computation to cross into SSD-land.
- This is the first Pi record in the PC era to be done using network storage. All previous Pi records going back to 2009 were done with storage directly attached to the systems itself - either directly to the motherboard, or through PCIe storage controllers.
- This is the first such computation to utilize the AVX512 instruction set.
- This is the second Pi record done with y-cruncher that has encountered and recovered from a silent hardware error.
- The computation racked up a total of 10 PB of reads and 9 PB of writes. 9 PB of writes is enough to destroy the average consumer SSD 10 times over.
- The speed of this computation was 8-to-1 bottlenecked by the storage bandwidth. The worst it has ever been in the current era.
| Date | Event |
| September 13, 2018 | Begin computation of 31.4 trillion digits of Pi. |
| September 22, 2018 | Computation is scapped and restarted due to an environment configuration issue that disconnected all the swap drives. |
| November 24, 2018 | A bug is discovered in y-cruncher. After some calculations, I determined the chance of it affecting Emma's computation to be ~2%. |
| December 8, 2018 | y-cruncher encounters the notorious "Coefficient is too large" error. The cause is unknown, but is suspected to be I/O instability. |
| December 9, 2018 | The computation is resumed from the last checkpoint and successfully progressed past the spot of the error. |
| December 27, 2019 | The BBP verification runs are kicked off. |
| December 29, 2019 | The BBP verification runs are completed. |
| December 31, 2019 | The computation finishes the series summation. |
| January 11, 2019 | The computation finishes writing out the hexadecimal digits. Emma contacts me saying that they match the BBP results! |
| January 17, 2019 | The base conversion is complete and the decimal digits are written out. |
| January 21, 2019 | Output verification is complete. Spot checks show no discrepancies with Peter Trueb's 22.4 trillion digits. |
{kind=link}
Coincidentally, the computation finished 10 years and 2 days after the release of the very first version of y-cruncher. #10YearChallenge
Like most of the previous computations, this latest one of 31.4 trillion digits had a number of firsts.
First Pi Record on a Cloud Service:
This is the first Pi record to be done on a commercial cloud service. Thus proving that cloud services are able to compete with both supercomputers as well as custom-built PCs for this kind of high performance computing. This also means that it is no longer necessary to get up close and personal with the hardware.
While this is the first time a cloud service was used for a Pi record, it isn't the first of any constant. Back in 2015, the Lemniscate constant was computed to 15 billion digits using Amazon Web Services. And currently, there is an undisclosed computation of another constant that was done on the Google Cloud that is still pending verification.
The thing with these computations is that they were small and the entire computation had fit onto a single cloud node. The problem with Pi is that because it is the most popular constant, it has been computed to so many digits that any record attempt for Pi would require hundreds of TB of storage space. This is too large to fit on even the largest and most expensive cloud nodes of any vendor.
What Emma proved here is that the storage limit can be overcome by utilizing storage nodes - a lot of them. Even though the traffic is now going over the network, it was still sufficient for the purposes of setting the Pi record even if that did turn out to be the largest performance bottleneck.
Will future computations continue down this route? Only time will tell...
First Pi Record on SSDs:
Historically, SSDs were never used for such computations. Furthermore they were (and still are) discouraged for such computations. The reasons are as follows:
- SSDs have a much higher cost per byte than hard drives.
- SSDs tend to have less capacity than hard drives. Thus requiring the use of more expansion slots to acquire the storage space that is needed.
- The main advantage of SSDs over mechanical hard drives is lower seek latencies. But y-cruncher has been optimized to not need low seek latencies.
- SSDs have limited write endurance. Computations of this size will require many petabytes of writes, but modern SSDs can't really handle this and will be "consumed" during a computation. Thus computations like this will have a non-fixed cost from replacing SSDs due to write wear.
This latest computation is the first to overcome all of these. In retrospect, this was probably unnecessary, but it does prove that it is possible.
First Pi Record done with AVX512:
y-cruncher has historically been kept up-to-date with the latest micro-optimizations and hardware-specific features. The spacing of Pi records in the current era (once every 1-2 years) is long enough that every other new record picks up a new round of optimizations. This time it picked up the massive AVX512 instruction set.
In recent years, the effects of micro-optimizations like this have been rendered increasingly irrelevant for large computations due to the disk bottleneck. But nevertheless they do provide substantial speedups when working within physical memory. If anything, the AVX512 might've been more effective for power efficiency than for reducing actual run-time.
The primary performance bottleneck for this computation is the storage bandwidth. While this has also been the case for at least the previous 5 computations, it's worth pointing out the severity of the bottleneck.
Here is the breakdown of the CPU utilization for all 6 Pi records done using y-cruncher:
| Date | Digits | Who | CPU Utilization |
| January 2019 | 31.4 trillion | Emma Haruka Iwao | 12% |
| November 2016 | 22.4 trillion | Peter Trueb | 22% |
| October 2014 | 13.3 trillion | Sandon Van Ness "houkouonchi" | 36% |
| December 2013 | 12.1 trillion | Shigeru Kondo | 37% |
| October 2011 | 10 trillion | Shigeru Kondo | ~77% |
| August 2010 | 5 trillion | Shigeru Kondo | 35.89% |
With the exception of the first two computations by Shigeru Kondo, there is a clear downward trend in CPU utilization. While y-cruncher isn't perfectly parallelized, it is good enough that any significant drop below 90% is usually caused by disk I/O.
What you are seeing here is the memory wall. And while it's usually discussed for the RAM/memory, it applies equally to disk/storage. In recent years, computational power has grown very quickly while storage has largely remained stagnant.
In the modern era:
- Memory speeds are 1.5 - 3x slower than is ideal for y-cruncher. In recent years, increasing competition between AMD and Intel has been driving up core counts without the necessary increases in memory bandwidth.
- Storage speeds are 3 - 20x slower than is ideal. Likewise, this is also growing rapidly for the same reason.
In recent years, the y-cruncher project has directly attacked the memory wall with increasingly aggressive optimizations. But there is a limit before the algorithms and implementations become "memory optimal". As of 2018, y-cruncher is nearing this limit. So there is little further room for improvement without some new breakthrough. Likewise, the complexity of these memory optimizations is at the point where the code is becoming difficult to manage.
In this latest Pi computation, the disk/storage bandwidth was about 2-3 GB/s which led to an average CPU utilization of 12.2%. Or about an 8-to-1 bottleneck. To put this into perspective:
- Given infinite storage bandwidth with the same CPU hardware, this computation would have taken 2 or 3 weeks.
- Given infinite computational power with the same storage setup, this computation would still have taken around 4 months.
In the past, the limiting factor for storage bandwidth were the hard drives themselves. But in this computation, it was the network bandwidth to the storage nodes. Write bandwidth was artificially capped to about 1.8 GB/s by the platform. Read bandwidth, while not artificially capped, was still limited to about 3.1 GB/s by the network hardware. It didn't matter that the devices themselves were SSDs, it was all held back by the network anyway.
To put it simply, 2-3 GB/s isn't enough. Because of how low it was, the only thing that mattered was the speed and efficiency of the storage access. Computation is effectively free. Thus, all the computational improvements in the past two years for both software and hardware (such as AVX512 and the Skylake architecture) were rendered more-or-less inconsequential. I often get asked about the use of GPUs. Well... GPUs aren't going to help with this kind of storage bottleneck.
In the current era, we need upwards of 20 GB/s of storage bandwidth to keep up with the available processing power on a typical high-end server like the one used for this computation. 20 GB/s is less than two PCIe 3.0 x16 slots. So in theory, this is possible. But it requires a level of hardware customization that we have yet to see.
If we had 20 GB/s of storage bandwidth, the computation would likely have taken less than 1 month. Thus in the current era, whoever has the biggest and fastest storage (without sacrificing reliability) will win the race for the most digits of Pi.
This computation is the 6th time that y-cruncher has been used to set the Pi record. It is the 4th time that featured at least one hardware error, and the 2nd that had a suspected silent hardware error. Hardware errors are a thing - even on server grade hardware. And it's clear that they aren't going away anytime soon.
Normal (non-silent) hardware errors are not a problem. The machine crashes, reboot it and resume the computation. Circuit breaker trips, turn it back on and resume the computation. Hard drive fails, restore from backup and resume the computation... This is (mostly) a solved problem thanks to checkpoint-restart. The only remaining issues stem from incomplete coverage of checkpoint-restart - which is just a matter of unfinished development work rather than a research problem.
However, silent hardware errors are much scarier. By definition, they are silent and do not cause a visible error. Instead, they lead to data corruption which can propagate to the end of a long computation resulting in the wrong digits. This is the worst scenario because you end up wasting a many-months long computation and have no idea whether the error was a hardware fault or a software bug. Because of this possibility, y-cruncher has many forms of built-in error-detection that catch errors as soon as possible to minimize the amount of wasted resources as well as minimizing the probability that a computation finishes with the wrong results.
It is this error-detection that bailed out two computations and saved them from the bad ending. But while this sounds like it worked out fine, it isn't actually scalable.
Empirical evidence from actual (unintended) hardware errors as well as artificially induced errors by means of overclocking suggest that y-cruncher's error-detection only has about 90% coverage. Meaning that 1 in 10 silent hardware errors will go undetected and lead the computation finishing with the wrong digits. The two errors that have happened so far were both lucky to land in that 90%. But if nothing is done to improve the coverage of the error-detection, it will only be a matter of time before an error slips through and triggers the death flag.
The obvious solution is to improve the error-detection coverage. But unfortunately, it isn't as easy as it sounds. The current 10% without coverage is the long tail of code that is either very difficult to do error-detection, or would incur an unacceptably large performance overhead. So we're kinda stuck between a rock and a hard place.
And we're just talking about hardware errors here. Let's not forget the possibility of software bugs that can have the same effects. After all, software is only as good as its developer. The mitigating factor here is that error-detection doesn't distinguish between hardware or software errors. So while the error-detection is meant for hardware errors, it is just as effective in catching software bugs.
Personally, I am most fearful of silent hardware errors. While it has yet to happen at such a stage, it's easy to picture how it might play out:
- Someone invests a large amount of time and money into a large computation. The digits don't pass verification.
- The person contacts me asking for help. But I can't do anything. All that investment is lost.
- Lot of distress on both sides. Maybe lots of finger-pointing.
For this reason, I typically discourage people from running computations that may take longer than 6 months. Likewise, I also discourage parties from attempting such a computation if it seems like they don't really know what they are doing or if they don't understand the risks involved.
y-cruncher is currently 6/6 in world record Pi attempts that have run to completion. But there is some amount of luck to this. Therefore one must not become complacent by the perfect record. A failed computation will happen at some point. It's just a matter of when. After all, world records with competition are not going to be easy to beat. And being able to run record-sized computation does not guarantee that it will actually result in a new record.
Load Imbalance with Thread Building Blocks (TBB):
y-cruncher lets the user choose a parallel computing framework. The previous Pi record by Peter Trueb used y-cruncher's Push Pool framework. For this computation, we decided to use Intel's Thread Building Blocks (TBB). This decision was made based on some simple benchmarks. But it later on, it turned out that TBB suffers severe load-balancing issues under y-cruncher's workload. Emma also noticed similar anomalies on the main computation. By comparison both Intel's own Cilk Plus and y-cruncher's Push Pool had no such problems. The result was a loss of computational performance.
In the end, this didn't matter since the disk bottleneck easily absorbed any amount of computational inefficiency. But it leaves behind a frustrating situation for the future where TBB is worse than Cilk Plus, yet Intel (which owns both) is getting rid of Cilk Plus in favor of TBB. It is currently unknown why this is the case.
There were numerous issues with deployment. Examples include:
- The were performance issues with live migration due to the memory-intensiveness of the computation. (The 1.4 TB of memory would have been completely overwritten roughly once every ~10 min. for much of the entire computation.)
- There were timeout issues with accessing the external storage nodes.
We expect to go into more detail on these at Google Cloud Next '19...