User Guides - Swap Mode
By Alexander Yee
(Last updated: February 6, 2024)
This guide explains how to use the various features in y-cruncher that are related to swap mode. This page has been updated for v0.8.3 which has changed significantly from older releases.
|
|
| Shigeru Kondo uses 32 hard drives to compute 12.1 trillion digits of Pi. |

Index:
- What is Swap Mode?
- Enabling Swap Mode
- Far Memory Configuration
- Far Memory Frameworks
- Far Memory Tuning
- Checkpointing
- Working Memory
- The I/O Benchmark
- Resuming an Interrupted Computation
- Dealing with Failures
- Undetected Errors and Failed Computations
- A Note About Solid State Drives (SSDs)
- Appendix:
Back To:
Swap mode is a feature that allows computations to be performed using disk/storage. This makes it possible to do computations that would otherwise not fit in main memory. In academia, this is known as "out-of-core computation". It is currently the only way to perform trillion digit computations on commodity hardware.
Thus, swap mode is similar to the operating system page file, but orders of magnitude more efficient.
The use of storage implies either mechanical hard drives or solid state flash. Both are much slower than ram. So to improve performance, the usual solution is to run many drives in parallel. Since it is rare for off-the-shelf computers to have such configurations, a significant amount of customization is generally needed to build a system that's suitable for efficiently running large computations in swap mode. (16 or more hard drives or 4 or more SSDs is typical for a high-end system)
Hard Drives (HDs) vs. Solid State Drives (SSDs):
Historically, the perferred storage medium was hard drives. They existed first and are cheaper and larger. However, they are very slow. As of 2023, the gap between hard drive and CPU performance has grown so large that it is practically impossible for hard drives to achieve sufficient bandwidth to keep up with CPU computation. (>100 hard drives for a high-end server.)
Thus, solid date drives (SSDs) are increasingly becoming popular. However, they come with some major drawbacks:
- Smaller in capacity. Thus it is more difficult to cram enough of them into a single system to achieve the total storage needed to set a Pi record.
- More expensive than mechanical hard drives.
- Limited write endurance which could be exceeded in just a single large computation (like a Pi record attempt).
- High-density QLC-based SSDs can have sustained write speeds that are slower than even hard drives.
In practice, y-cruncher's workload has low write amplification. So it will be able to exceed the TBW of an SSD several times over before S.M.A.R.T. shows it as reaching end-of-life. Recent results on enterprise SSDs seem to suggest that it is even better there.
Important Concepts:
In order to effectively use swap mode, there are several concepts and design explanations will be useful to understand.
At the highest level, swap mode is mathematically the same as ram only mode. The only difference is the storage medium. Ram only mode uses ram for storing data. Swap mode uses "far memory" to store data.
So what is "far memory"? It is any memory that is "far away" from ram. This will almost always be the file system which can reside either on hard drives, SSDs, or even network/cloud storage. In essence, "far memory" is an abstraction layer.
In swap mode, all the data "lives" in far memory. Ram becomes a cache for far memory. And by necessity, any computation must first load the data from far memory into ram and write it back later. By comparison, ram only mode will usually directly operate on data since it's already in ram.
Thus in swap mode, the program is divided into two separate components:
- The computation side.
- The far memory side.
The computation side of y-cruncher is where all the math and computation happens. It accesses far memory by explicitly reading/writing to it.
Far memory is the entire storage subsystem. It receives the read/write requests from the computation layer and handles them as efficiently as possible.
The two sides are completely separate. Each side has no visibility into the other - thus a separation of concerns in software design.
Because of this abstraction layer, there are different implementations of far memory which you can choose from. This is similar to the parallel frameworks and memory allocators.
Obviously, there are performance implications to having a full separation between the two sides. If the computation side has no knowledge of the underlying far memory, it cannot optimize its access patterns for it.
Examples:
- Hard drives have very expensive seeks so the computation may perfer to trade away disk seeks for more total I/O in bytes.
- Many SSDs have a fast SLC cache. It can be beneficial to exploit spacial locality* to minimize thrashing on the SSD's slow TLC or QLC write speeds.
To get around the information barrier caused by the hard separation between compute and far memory, swap mode has a concept of "Far Memory Tuning".
Far memory tuning, is information that describes the performance characteristics of the underlying far memory. For example, it contains:
- How expensive seeks are relative to sequential read/write.
- Is it beneficial to parallelize accesses to far memory? If so, what kind of parallelism?
- Are there are any fast regions due to caching. Or more generally, the entire topology of hierarchical storage*.
*This feature is not yet available. It is planned for v0.8.4 or later.
Naturally, the information contained in the far memory tuning should accurately describe the actual far memory implementation. But from a correctness standpoint, it doesn't matter. Even if the far memory tuning is completely wrong, the computation will still run correctly - albeit with (potentially large) performance loss.
Thus, it is the user's responsibility to accurately specify the far memory tuning settings in order to maximize performance of a swap mode computation.
Beyond performance, the separation of far-memory and far-memory-tuning is commonly used as a developer testing tool. For example one of y-cruncher's many quality-control/regression tests is to run many different sets of tuning settings against a ram drive as far memory instead of actual storage to make them run faster. (Why do you think my machines have 100s of GB of ram?)
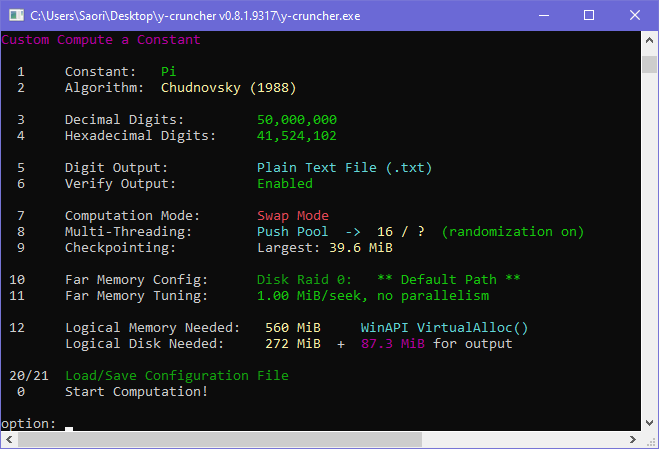
y-cruncher is meant to be easy to use for the casual overclocking enthusiast. Therefore, the very first two options in the main menu are for benchmarks and stress-tests. Since swap mode is a non-trivial feature that's difficult to use correctly, it is well hidden.
As of version 0.7.8, Swap Mode can be enabled as follows:
- Launch y-cruncher. (On Windows, you also need to run as administrator.)
- Select Option 3: "Custom Compute a Constant"
- Select Option 8: "Computation Mode"
- Select Option 2: "Disk Swapping"
If you did everything correctly, it should look like the screenshot to the right.
Now is a good time to get yourself familiar with the Custom Compute menu if aren't already. This is essentially the "real" main menu that lets you access all the computational features of y-cruncher.
Options 0 - 8 are pretty self-explanatory and are not specific to Swap Mode. So we'll skip those.
Far Memory Configuration: (Option 10)
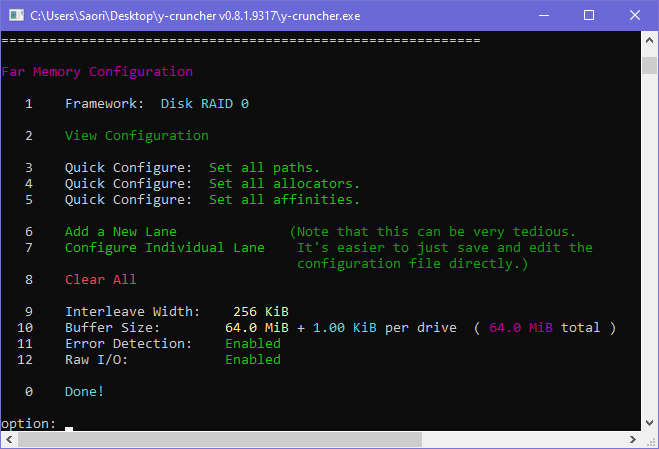
What is Far Memory?
This is the configuration of the storage system. This is where you specify the paths of all the hard drives (or SSDs) along with other settings.
The term "far memory" is a generic term for any memory that is far away from the processor. Though historically it has always been just an array of hard drives or SSDs.
The options available here will depend on which framework is selected.
As of v0.8.3, there are only two far memory frameworks.
- Disk RAID 0: This is the new RAID 0 framework that should always be used now.
Legacy RAID 0/3: This is the old RAID 0/3 from older verisons of y-cruncher. It has been superceded by the new RAID 0 framework.- Ram Drive - C malloc(): Allocate in ram. Don't use disk storage.
The Disk RAID 0 is new to v0.7.8 and is now the standard framework for all swap mode computations. Unlike the legacy RAID 0/3, it is specialized for RAID 0 and is newer and better optimized for that purpose. It also supports checksumming which will detect silent I/O data corruption.
The structure of the RAID 0 is a straight-forward array of "lanes" where each lane represents a drive. Data is interleaved across all the lanes in a cyclic manner.
As of the current design (v0.8.2), each lane has its own I/O buffer and worker thread which are all independent from all other lanes. This allows the lanes to operate in parallel to utilize the full combined bandwidth of all the lanes.
Starting from v0.8.3, each lane can have multiple I/O buffers and worker threads. This improves bandwidth on SSDs by increasing CPU+I/O overlapping as well as queue depth.
Quick Configure: Set all paths. (Option 3)
For most casual users, this is the only option you need to use. This lets you set the paths for each of the RAID 0 lanes.
Tips:
- Use empty and freshly formatted drives for best performance.
- Got too many drives? Not enough drive letters? Use NTFS Volume Mount Points.
Set Tuning Defaults: (New to y-cruncher v0.8.3)
Hard drives and Solid State drives have very different performance characteristics that warrant different settings. These options let you quickly load the optimized defaults for each type of storage.
| Hard Drives (HDs) | Solid State Drives (SSDs) | |
| Interleave Width: | 64 KB | 4 KB |
| Lane Multiplier: | 1 | 2 |
| Workers per Lane: | 1 | 2 |
| Buffer Size: | 64 MB per worker | 1 MB per worker |
| Raw I/O: | Enabled | Enabled |
| Bytes per Seek: | 1 MB x (# lanes) | 256 KB x (# lanes) |
Selecting one of these options will overwrite all the listed settings. They will also change the Far Memory Tuning defaults. These options are global and apply to the entire drive array. You cannot customize them on a per-lane basis. It's not recommended to mix hard drives and SSDs anyway.
Notes:
- The interleave width should no smaller than the hardware's sector size. Hard drives larger than 16TiB will (by default) have sector sizes larger than 4 KB. So the settings here will default to 64 KB which should be plenty of room for future larger hard drives.
- Workers/lane is 1 for hard drives because they perform poorly under parallel access due to the extra seek overhead.
- Workers/lane is 2 for SSDs because SSDs require I/O parallelism (and a queue depth) to achieve the high bandwidth. Multiple workers also allows the framework to parallelize the CPU work of striping/copying with the actual I/O.
- Raw I/O should always be enabled. OS disk caching is actively detrimental to performance and functionality. The only reason why you would ever want to disable this is if you are using some sort of network or object file storage emulation of a filesystem that doesn't like or doesn't support raw I/O.
- Buffer size is the largest contiguous block of I/O that can be issued. Since hard drives have high seek times, a larger buffer size is needed to reduce disk seeks.
- For SSDs, it is quite easy to saturate memory bandwidth from just I/O. For example, 4 high-end PCIe 4.0 NVMe SSDs will achieve >16GB/s of I/O which (after applying software overhead) will saturate the memory bandwidth of an AM5 platform. If this is the case, the buffer size should be small enough to fit comfortably in the CPU cache - hence the 1 MB default. Otherwise, a larger buffer size (> 8 MB) may be beneficial to reduce OS API overhead.
- Bytes per Seek is higher for hard drives because hard drives have very expensive seeks compared to SSDs.
- While SSDs can be efficient for even 4 KB random access, this is not the case here. The current implementation has too much OS overhead to efficiently handle super-small sizes. In short, the framework is optimized for large sequential bandwidth and not for small block IOPs.
Buffer Size:
This controls the size of the I/O buffer. This buffer is needed to perform the sector alignment and RAID interleaving. Larger buffers may increase efficiency, but will also use more memory.
The value specified here is per lane and per worker thread within each lane. So the total size of all the buffers is:
Total size of all buffers = (buffer size) x (# of lanes) x (workers per thread)
Because of the way the implementation works, the buffer is always rounded up to a multiple of the interleave width.
All disk accesses must go through the I/O buffer. This has the following performance implications:
- The largest sequential block that can be read/written is the size of the buffer.
- Each disk access may require up to 3 disk seeks. (One for the block, and one for each of the boundaries due to read-modify-write.)
If the underlying device has a very high "bytes per seek", it may be beneficial to use a larger buffer.
Error Detection:
This option enables/disables the checksum error-detection that will detect silent disk I/O errors. It comes with some performance overhead.
When an error is detected, it halts the computation. Since this is an error-detection only feature, it cannot actually recover from errors.
Error-detection is enabled by default because:
- The space overhead is negligible. (< 0.1%)
- The performance overhead has been measured to be acceptably small. (and further optimized in v0.8.3)
- Disk I/O simply cannot be trusted anymore. (not that it ever should've been trusted in the first place...)
The checksum length is 31 bits. Barring software bugs, the probability of a random error slipping through is 1 in 231.
Interleave Width:
Advanced Option: Don't change unless you know what you're doing!
The interleave width (or stripe size) controls 4 things:
- The granularity of the RAID interleaving.
- The granularity of the checksumming.
- The alignment for all accesses to the device.
- The alignment of the I/O buffers.
The interleave width is an integer (the number of bytes) and must be a power-of-two. When raw I/O is enabled, it must also be at least the sector size of the underlying device. Otherwise, I/O operations may fail.
Smaller widths have better load distribution and are more efficient with small random accesses, but they also have more overhead. Prior to v0.8.3, the default width is 256 KB. This also means that by default, all access are done in 256 KB blocks regardless of size. On paper, this sounds inefficient for small random accesses. But in reality, y-cruncher (by design) never does kind of access in volume.
Starting from v0.8.3, the default width has been decreased to its minimum allowed value of 4 KB which is the native sector size of most devices. The overhead of the checksums for this is 0.1%. So a 1 TiB swap file will have 1 GiB of checksum overhead.
Lane Multiplier: (New to y-cruncher v0.8.3)
Advanced Option: Don't change unless you know what you're doing!
For each path, split it into this many lanes. This is essentially a reverse RAID 0.
When the lane multiplier is larger than 1, the framework will treat each path as if they were multiple independent drives and will stripe them accordingly. Accesses will then be parallelized across the lanes resulting in parallel access to the same path.
The motivation here is for drives that require I/O parallelism and high queue depth to achieve maximum bandwidth. (namely SSDs)
Workers per Lane: (New to y-cruncher v0.8.3)
Advanced Option: Don't change unless you know what you're doing!
Each worker consists of an I/O buffer and a thread. And each lane has at least one worker.
The defaults are:
- Hard Drives: 1 worker/lane
- Solid State Drives: 2 workers/lane
Increasing the # of workers increases the amount of I/O parallelism at the cost of higher CPU overhead and less sequential access. Some SSD-based arrays will find that 4 workers/lane to be better than the default of 2.
Raw I/O:
Advanced Option: Don't change unless you know what you're doing!
This option lets you enable or disable raw and unbufferred I/O. Raw I/O allows all I/O operations to bypass the OS buffer and go directly to the device. But it requires that the program respect the sector alignment of the device.
When enabled, this option sets the FILE_FLAG_NO_BUFFERING in Windows and the O_DIRECT flag in Linux respectively.
This option should not be disabled except for debugging purposes. Raw I/O is not just an issue of performance, it is sometimes needed to prevent the "thrash of death" where the OS is so aggressive with disk caching that it pages itself out of memory and leaves the system completely unresponsive.
Per Lane Options:
In addition to the global settings above, there are a number of settings that can be configured on a per-lane basis.
- Path
- BufferAllocator
- WorkerThreadCores
- WorkerThreadPriority
These can be configured individually using option 7 or in bulk using options 4 and 5. But that's very tedious, so you should save and edit the configuration file directly.
Path is self-explanatory. It's where the data for that lane goes.
BufferAllocator is the memory allocator that is used to allocate the I/O buffer for the lane. Since this is configurable on a per-lane basis, you can micromanage the NUMA placement of the buffer memory for each device. For example, if one device is close to one NUMA node, you can put its I/O buffer on that node.
WorkerThreadCores is the core affinity of the worker thread for that particular lane. If the list is empty, no affinity is set and will have whatever the default is. You can use this option with BufferAllocator to bind both the memory and the worker thread for a lane to particular NUMA node(s). On Windows, all cores in this set must be on the same processor group.
WorkerThreadPriority controls the thread priority for the worker thread. Higher numbers are higher priority. The exact numbers are OS-specific. By default, I/O worker threads are at high priority to avoid getting starved by computational threads.
This one is simple. Don't use disk. Instead, dynamically allocate everything in memory. In essence, this is an optimized ram drive that bypasses the file system.
Intuitively, this sounds useless since it defeats the purpose of swap mode. But it has been used extensively for internal testing.
While untested, this option may be a way to improve performance on systems with large amounts of explicit HBM (high bandwidth memory). The idea here is to have the program run entirely in HBM as if it were memory, then use ram as the "far" memory.
As everything is run in memory, be aware of the following caveats:
- Make sure you have enough memory for both the working memory and the swap space.
- Checkpointing is not supported since no persistent files are ever created.
Far Memory Tuning: (Option 11)
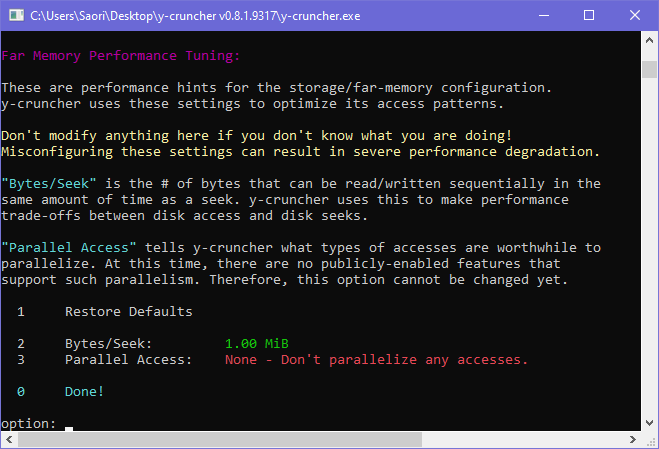
What is Far Memory Tuning?
While the "Far Memory Configuration" controls the makeup of the far memory, it has no influence on how y-cruncher performs its computation.
However, different configurations have different performance characteristics. Thus, the "Far Memory Tuning" menu lets you communicate this information to the program so that it can optimize its algorithms and access patterns.
The "Bytes/Seek" parameter is the # of bytes that can be read sequentially in the same amount of time as a seek. It is measure of the relative cost of a disk seek with respect to the sequential access bandwidth.
This parameter is important for algorithm selection. For large computations that require orders of magnitude more storage than there is physical memory, y-cruncher will need to choose between algorithms that have more disk seeks vs. algorithms that have more disk access (in bytes). Setting this parameter wrong can result in the program choosing suboptimal algorithms. It the worst case, the consequences can be severe performance degradation.
The "Bytes/Seek" parameter value applies to the entire drive array, not the individual drives. Since y-cruncher's computational code has no visibility into the configuration of the far memory, it has no knowledge of the individual drives. All it sees is a single large "far memory" device.
Examples:
As of 2019, most high-end hard drives have a sequential bandwidth of about 200 MB/s and a seek time of about 10ms. This means that in the time it takes to perform a seek (10ms), the hard drive could have done about 2 MB of sequential I/O. Therefore, the Bytes/Seek parameter is 2 MB for a single hard drive.
What if we have 4 hard drives in RAID 0?
Using the same numbers as above, the seek time of the entire array is still about 10ms. But the total bandwidth is quadrupled to 800 MB/s. So while the Bytes/Seek for each individual drive is still 2 MB, the Bytes/Seek for the entire array is 8 MB. Therefore, you must set the Bytes/Seek parameter to 8 MB.
If you don't touch the Bytes/Seek parameter, the menu will automatically adjust it based on the far memory configuration you have set. But the moment you manually override it, it stops doing this for you since it assumes you are now taking control of the setting.
What are the consequences of improperly setting the Bytes/Seek?
For computations that only require slightly more storage than there is memory, it won't matter. The majority of casual swap-mode computations fall into this category. But if you're running something very large (like a world record) where the storage requirement is 100x more than your memory, then the parameter will probably matter.
If the Bytes/Seek is too small:
y-cruncher thinks disk seeks are faster than they really are. So it will pick algorithms that do less disk I/O (in bytes), but at the cost of more disk seeks. Therefore if the "Bytes/Seek" is set too low, the computation will spend a very large amount of time performing disk seeks rather than useful disk I/O.
If the Bytes/Seek is too large:
y-cruncher thinks disk seeks are slower than they really are. So it will pick algorithms that do fewer disk seeks at the cost of more disk I/O (in bytes). Therefore if the "Bytes/Seek" is set too high, the computation will be doing a lot of unnecessary disk I/O.
The trade-off is usually quadratic. Reducing the Bytes/Seek parameter by a factor of 2 will:
- Reduce the amount of disk I/O (in bytes) by up to a factor of 2.
- Increase the number of disk seeks by up to a factor of 4.
Therefore, there is a much higher risk to setting the Bytes/Seek too low than too high.
Why can't y-cruncher automatically detect the Bytes/Seek?
The only way to do that is through a benchmark. But an automated benchmark is time-consuming and very error-prone to corner cases. Therefore, the only reasonable option is to defer to the user.
What's going on internally?
The use-case for the Bytes/Seek parameter is in the disk-swapping FFT algorithms.
It is almost always possible to perform a disk-swapping FFT with only 2 passes over the dataset. But the larger it is with respect to the amount of physical memory, the more disk seeks are required.
The # of disk seeks needed to perform a 2-pass FFT is asympotically:
The square in this equation is what causes the quadratic trade-off mentioned earlier. If the data size is many times larger than the physical memory, the number of disk seeks can be so large that the computation literally spends all its time doing seeks and nothing else.
If the Bytes/Seek parameter is properly set, y-cruncher will recognize when the 2-pass algorithm becomes problematic due to disk seeks. It will then switch to multi-pass algorithms that require far fewer disk seeks: 3-pass, 4-pass... as many as necessary. But more passes over disk requires more disk I/O in bytes.
This option is a placeholder for some future plans as it is not useful with y-cruncher's current functionality.
This option controls what types of I/O access is beneficial to parallelize. Historically with mechanical hard drives, there is no benefit to parallelizing disk access. But this is no longer the case with SSDs, deep NCQs, and bidirectional network connections.
Starting from v0.8.3, y-cruncher will support parallel I/O both for computation and for I/O access. Thus this option is not useful until v0.8.3 is released.
The defaults are:
- Hard Drives: No Parallelism
- Solid State Drives: Parallelize reads with writes.
Checkpointing (checkpoint-restart) allows the computation to be saved and resumed later. This enables computations to survive interruptions such as power outages or system crashes. It also enables hardware changes in the middle of a computation.
Checkpoint is enabled by default in swap mode. As a computation progresses, y-cruncher will automatically create them. To resume a checkpoint, just re-run y-cruncher from the same directory before. It will find the unfinished computation and resume it.
Version 0.7.8 has several additions to the checkpoint-restart capability:
- The ability to turn off the checkpointing.
- The ability to run a system command after each checkpoint is made.
- An upper-bound estimate for the size of the largest checkpoint.
The performance overhead of checkpointing is small to negligible by design. Establishing a checkpoint consists only of renaming a few files, writing the (small) checkpoint metadata file, and flushing any disk caches.
Checkpoint Mechanics:
When a checkpoint is created, it consists of two things:
- A file named, "y-cruncher Checkpoint File.txt" that contains all the metadata for the computation. It is a readable text file.
- One or more swap files with the word, "checkpoint" in their names. These will reside in the swap paths that you have provided.
In order to resume a checkpoint, both of the above need to be present in their original locations. If there are multiple swap paths, all the files with, "checkpoint" in their names in all the paths are needed. Everything without "checkpoint" in its name is not needed and will be deleted automatically by y-cruncher upon resume.
Checkpointing is inherently tied to swap mode. This means that checkpoints are only created when disk swapping is needed. If there is no disk swapping, there is no checkpointing - thus Ram Only mode has no checkpointing.
y-cruncher does not perform disk swapping until it runs out of memory. Since there are no checkpoints at the start of a computation, it may be a long time before one is finally created - especially if you have a lot of memory and the computation is for a slow constant.
Once a checkpoint is created, new checkpoints will overwrite the old ones. This is done in a fail-safe manner where the lifetimes for both checkpoints will overlap such that a failure at any moment will guarantee that at least one checkpoint survives. During this overlap period, the new checkpoint file will be named, "y-cruncher Checkpoint File (new).txt". Once it is created, the old checkpoint is deleted and the new one renamed. Should the computation be interrupted at just the right time, you may need to manually rename, "y-cruncher Checkpoint File (new).txt" -> "y-cruncher Checkpoint File.txt" in order to resume the computation.
When a computation finishes, the last checkpoint is automatically deleted.
Stacked Checkpointing:
New to y-cruncher v0.8.3 is the ability to keep multiple checkpoints. When this happens you will have multiple checkpoints to choose from should the program get interrupted.
Checkpoint files starting from y-cruncher v0.8.3 will be named as follows:
- y-cruncher Checkpoint File - 0.txt
- y-cruncher Checkpoint File - 1.txt
- y-cruncher Checkpoint File - 2.txt
- ...
The larger the number, the newer the checkpoint. When you launch y-cruncher, it will automatically pick the newest checkpoint it finds. Thus you can force it to pick an older checkpoint by deleting the newer files.
Multiple checkpoints will happen when a newer checkpoint contains all the files from an older one. That is, the files in the newer checkpoint are a superset of the older checkpoint. Thus, it is possible to roll further back since the older checkpoint is still intact. Only when new checkpoints remove files from older checkpoints do those older checkpoints get deleted.
If you are unsure what files are in each checkpoint, you can open the checkpoint file and read the list in there. It's a good idea to understand what's going on for when you need to resume a computation possibily not from the latest checkpoint should that be corrupted or bad in some way.
Notes:
Stacked checkpointing and the ability to roll futher back before the latest checkpoint is a precursor for enabling checkpointing within the final base conversion of a computation. For years, checkpointing was not supported in the base conversion because it is an in-place algorithm that constantly overwrites the same data. Thus it became difficult to safely checkpoint because each step could potentially corrupt the only checkpoint.
Stacked checkpointing will (in theory) allow the user to roll all the way back to before the base conversion even started. So if the base conversion fails midway in a manner that corrupts its local checkpoints, there will still be the option to roll all the back to a safe point.
Checkpointing is only useful if all the data is there and can be recovered. But for long computations with dozens of hard drives (or even SSDs), the probability of a catastrophic failure of at least one drive resulting in permanent data loss is real and cannot be ignored.
The only form of forward error-correction that y-cruncher supports is the old RAID 0/3. However, this was never a complete solution and the feature is now deprecated. As such, the only way to guard against such failures is to manually make backups of the checkpoints.
Checkpointing currently has zero overhead as it only involves renaming files. So it is enabled by default and there is no reason to disable it.
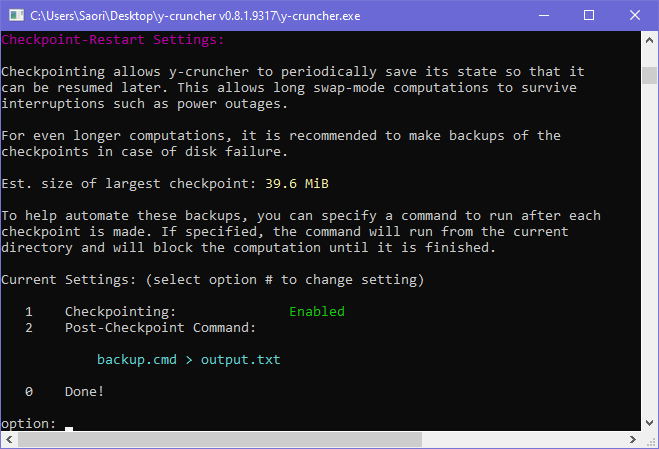
For super long computations where the user needs to do periodic backups, this can be tedious. This option allows you to automate this process.
If a command is set, y-cruncher will run it after each checkpoint is created. Thus you should insert a batch file that will automatically copy all the checkpoint files to a dedicated backup directory.
The computation will not resume until the script finishes.
Important:
- Make sure you rate limit the backups. y-cruncher sometimes will create multiple checkpoints in quick succession and you do not want to be copying out terabytes of data every time.
- Be sure you pipe the output of the batch script to a file. Failure to do so will result in the script's logging being dumped into y-cruncher's console output.
- Do not attempt any sort of asynchronous copy of the file. In other words, do not return until you are done copying because y-cruncher may overwrite the checkpoints as soon as it resumes.
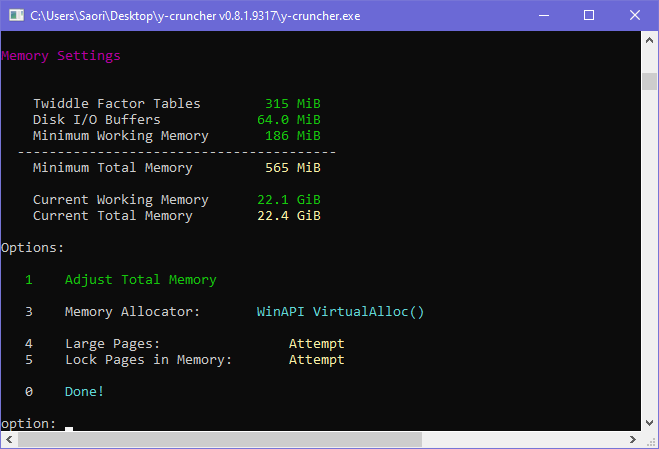
This is the last option available in the Custom Compute menu. It lets you choose the memory allocator as well as how much memory the computation should use.
y-cruncher uses memory as a cache for disk. So the more the better: Give it all the memory you have, but leave some room for the OS. By default, it will use about 94% of your available physical memory.
This menu also lets you configure the memory allocator.
Main article: Memory Allocation
Note that recent versions of Linux are eager to swap memory out to disk even when there is enough memory hold everything in ram. Unfortunately, y-cruncher gets caught up in this. When y-cruncher allocates memory, it expects it to be in memory and it treats it as such. So when the OS pages it out to disk, the result is extremely severe performance degradation.
There are 4 possible solutions to this:
- Disable the swap file. (tested and confirmed to work)
- Reduce the working memory. (works, but you may need to reduce it by a factor of 2 or more)
- Set the "swappiness" value to zero. (untested)
- Lock the pages in memory. (untested)

Its purpose of the I/O Benchmark is to measure the speed of your disk configuration and suggest improvements.
It will tell you: (example screenshot to the right)
- The disk bandwidth with sequential access pattern.
- The disk bandwidth in the worst case non-sequential access pattern.
- The relative disk bandwidth to the compute power of the processors.
This is the benchmark that can determine whether the "Bytes/Seek" parameter is set correctly.
Important Note:
The I/O benchmark can give misleading results if your SSDs support SLC caching.
If you intend to run a computation that uses the entire capacity of an SSD, a benchmark of only a small portion of the SSD will be swallowed by the SLC cache and thus not representative of the steady state to the drive's native TLC or QLC.
Sequential Read/Write:
This is pretty self-explanatory. As of 2017, most 7200 RPM hard drives will get about 150 - 200 MB/s of sequential bandwidth. Combine a bunch of them and you'll have a decent amount of bandwidth.
The example to the right is using 16 hard drives in RAID 0. Some of the drives are very old, so the performance of this array isn't great.
Threshold Strided Read/Write:
This is the measurement that tests whether the Bytes/Seek is set correctly.
It works by performing random access over the disk using block sizes equal to the Bytes/Seek value.
- If Bytes/Seek is set correctly, it will be approximately 1/2 of the sequential bandwidth as it spends an equal amount of time doing I/O vs. seeks.
- If Bytes/Seek is set too low, it will be very low and highlighted yellow or red.
- If Bytes/Seek is set too high, it will be very high and highlighted dark green.
Due to imbalances in y-cruncher's algorithms, the recommended value is about 1/3 of the sequential bandwidth as opposed to 1/2.
Because of the high penalty for having too low a Bytes/Seek parameter, you will want to avoid the red values.
Overlapped VST-I/O Ratio:
This is the relative speed of the disk array to the CPU compute power.
For very large computations, y-cruncher will spend a lot of time streaming data off the disk, crunching it in memory, and streaming it back. The disk I/O is often done in parallel with the computational work on data that's already in memory. So you get a "race" to see who finishes first.
The overlapped VST-I/O ratio is essentially a measure of which is faster. The streaming to and from disk? Or the computational work?
- Less than 1.0 means the disk is slower than the CPU. Disk bandwidth is the bottleneck.
- Greater than 1.0 means the disk is faster than the CPU. CPU compute power is the bottleneck.
For small computations (< 10x of physical memory), a ratio of 1.0 should suffice. Larger computations will be better served with a ratio of 2.0 or higher.
As of 2015, the unfortunate reality is that it will be very difficult for a high-end processor to reach a ratio of 2.0 with mechanical hard drives. It's much easier with SSDs, but as mentioned before, SSDs are not recommended as they are not guaranteed to last under a sustained y-cruncher workload. Hopefully the longevity of SSDs will eventually increase to the point where this is no longer an issue.
What to do:
Once you have your hardware and the disk configuration set up, there isn't much you can do with the software other than to optimize the Bytes/Seek value.
Play with it until the benchmark stops complaining about it and you're set. If the strided read and strided write speeds are drastically different for your system, this may not even be possible. If that's the case, err on the side of caution and make sure the lower of the two is not less than 1/4 of the sequential access.
The I/O benchmark lets you adjust the working memory size. It's usually best to use as much memory as you can. If you use less, disk caching from the OS may screw up the results. By default it will choose about 94% of your available physical memory. So you shouldn't need to change it.
Resuming an Interrupted Computation:
For long enough computations, bad things happen:
- The power goes out.
- The computer crashes.
- Windows decides to restart because you forgot to disable Automatic Updates...
Fortunately, y-cruncher will have created a file, "y-cruncher Checkpoint File.txt". (unless you're at the start of the computation - in which you haven't lost much anyway)
That file contains all the metadata state from the last checkpoint it made. It's a readable text file, that contains a list of all the swap paths as well as the execution stack-trace with filenames pointing to all the swap files that are needed to resume the computation.
Anyway, if you re-run the program, it will see that checkpoint file and resume from that checkpoint. Nothing else needs to be done.
If you want to give up on a computation, just delete that file.
But there are few things to note:
- The (deprecated) Raid 0+3 implementation has no integrity checks. If any of them corrupted, the computation will be (silently) doomed. (it will finish with wrong results) The new Disk Raid 0 implementation enables checksumming by default which will catch data corruption.
Without checksumming you must be very careful when resuming after an improper shutdown. (more details in the next section)
- The filenames across paths have the same name. But they are in folders of different names to make it harder to mix them up during backups.
- The checkpoint file itself, "y-cruncher Checkpoint File.txt", has a hash that prevents tampering. Upon resuming a checkpoint, the program deserializes that file directly into the internal state without sanity checks. So the hash is there to prevent you from shooting yourself.*
*Under extreme circumstances, such as being far into a very large (world record attempt) computation, and you hit a problem that requires editing the checkpoint file or some other intervention on my part, let me know and I'll see what I can do. I do have the ability to edit a checkpoint file and regenerate the hash. But since the program is not designed for such changes, there is no guarantee that such a hack will work and allow the computation to complete with the correct results.
Changes in v0.8.3:
As explained in an earlier section, y-cruncher v0.8.3 will support multiple checkpoints with the following names:
- y-cruncher Checkpoint File - 0.txt
- y-cruncher Checkpoint File - 1.txt
- y-cruncher Checkpoint File - 2.txt
- ...
The larger the number, the newer the checkpoint. If you launch y-cruncher and it detects a checkpoint, it will try to resume from the newest one. If you want to force it to resume from an earlier one, just delete the files for the newer checkpoints.
Why can't the checkpoint file be changed mid-computation?
In short, y-cruncher does not support the editing of parameters in the middle of a computation. The rules for what can and can't be changed will vary between versions of y-cruncher. And such a feature opens up several degrees of freedom in the program that needs to be tested and validated.
Most importantly, the majority of the things that are useful to change cannot be changed. Anything that affects the "computation plan" absolutely cannot be changed. And anything that fundamentally changes the swapfile configuration is not possible without some sort of converter which doesn't exist.
The following things affect the computation plan and fundamentally cannot be changed:
- The constant being computed.
- The algorithm/formula.
- The number of digits and working precision.
- The computation mode. (Ram Only vs. Swap Mode)
Things that conditionally affect the computation plan. It may be possible to change them under some circumstances, but still dangerous nevertheless.
- The program version.
- The task decomposition size.
- The working memory size.
- The bytes/seek parameter.
- The size of the I/O buffers.
The things that can be changed in theory, but require extra tools:
- The far memory configuration. This requires converting the swapfiles from one format to another. But y-cruncher has no feature that can do this.
The things that are always safe to change, but of course cannot change since y-cruncher locks down the checkpoint file:
- Enabling/Disabling the hexadecimal digits.
- The output path to write the digits.
- The compression format for the digits.
- The parallel computing framework.
- The directories for the swapfiles. (Provided that the swapfiles themselves are moved appropriately.)
As mentioned in an earlier section, things are going to go wrong when you have a lot of hardware running for a long time.
This section will show a bunch of different ways a computation can break down. It will also show how the program handles it and what you need to do to recover.
Something in the system crashes, and it is not y-cruncher. And somehow it manages to make the system inoperable.
What to do:
- Close y-cruncher and attempt to safely shutdown the computer.
- If you fail, go to "Unsafe Shutdown". Otherwise continue.
- Fix the problem. I can't help you here since this is an external issue.
- When ready, restart the program and it will resume from the last checkpoint.
This is a pretty broad range of failures. It covers everything from power outages to BSODs from hardware instability.
Any unsafe shutdown is bad. Because you don't know if the OS managed to flush the disk cache for the checkpoint files. y-cruncher does actually force a flush on the disk cache before establishing a checkpoint. But there is no guarantee that the OS or the hardware actually complies.
What to do:
- Figure out what caused the unsafe shutdown and fix that first.
- You have a tough decision to make: Do you want to trust that the checkpoint files are not corrupted?
A good way to help your decision is to look at the timestamp of when the checkpoint was created. If it was created hours before the unsafe shutdown, then you're probably safe. It's unlikely that the OS will not have flushed the buffers to that checkpoint in that long of a time.
If you don't know exactly when the shutdown occurred because it happened overnight or while you were away, you'll want to look at the last created/modified timestamps of the other files in the system. A good way is to look at the Windows Event Log. That can give a rough idea of when the machine went down.
If you discover that the checkpoint was made minutes or even seconds before the unsafe shutdown... well... that's your call. Ideally, you will have made a backup of an earlier checkpoint to fall back to.
If the far memory implementation supports checksumming, corruption will likely be detected when it is read.
There are a number of possibilities in this case. So let's get straight to the point:
- The hardware is unstable. Are you overclocking? Non-overclocked computers can go unstable as well... They're called "lemons". :P
- There is a bug in y-cruncher.
- There is a bug in the OS.
A bug in the OS is the least likely, but nevertheless, it has happened before.
What to do:
- If there is an obvious possible source of instability (overclocking, new hardware, etc...) - check that out first.
- Otherwise, if you are somewhat confident that the hardware is stable, then attempt to reproduce the crash.
- Re-run the program. If it made a checkpoint, then let it resume. Otherwise, re-run it with the exact same settings as before.
- If you get the same crash in roughly the same place. It's mostly like a bug in y-cruncher. Please let me know with all the details.
- In all other cases, you should suspect that the hardware is unstable.
y-cruncher is a multi-threaded program. But it is also (mostly) deterministic. It was designed this way to avoid the problem of heisenbugs - which are common in asynchronous applications and can be extremely difficult track down and fix.
Because of this determinism, crashes and errors that happen intermittently are more likely to be caused by hardware instability rather than a bug in y-cruncher.
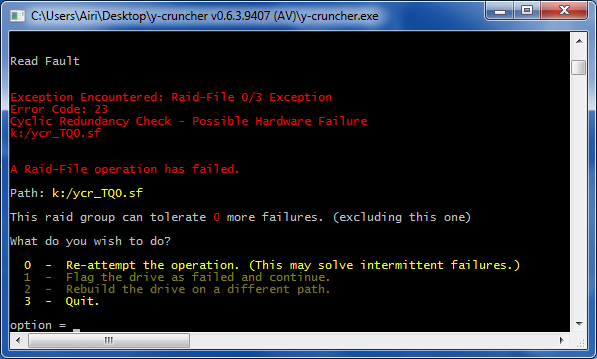
The "Raid-File" is the built-in raid system. When something goes wrong, it will throw an exception and print out the file that errored.
y-cruncher will recognize any of the following issues:
- Access Denied
- Path does not exist.
- Not Enough Memory
- Disk is Full
- Write Fault
- Read Fault
- Cyclic Redundancy Check - Possible Hardware Failure
- The device has been disconnected.
Most of these are pretty self-explanatory. 5 - 7 usually imply a hardware issue with either a hard drive or a disk controller.
Unless you have RAID3 in the setup, it's unlikely you'll be able to do anything to continue the computation on the fly. Sometimes you'll get an option to retry the operation, but from my experience, it rarely ever works.
So the only viable option is to quit the program and restart it. It will resume from the last checkpoint that was made. Which isn't bad at all.
But if you start getting these often, pay attention to what it's failing on. If it's always on the same drive... You might wanna replace that drive before it dies.
Older versions of y-cruncher (<= 0.5.5) were more aggressive in letting you retry failed disk operations. But this is no longer neccessary in v0.6.x because the checkpoint restart is much better.
Final Note: If you find that you are getting read errors on a checkpoint file. You are basically screwed since the current checkpoint is unreadable.
Hopefully you have made a backup of an earlier (non-corrupt) checkpoint.
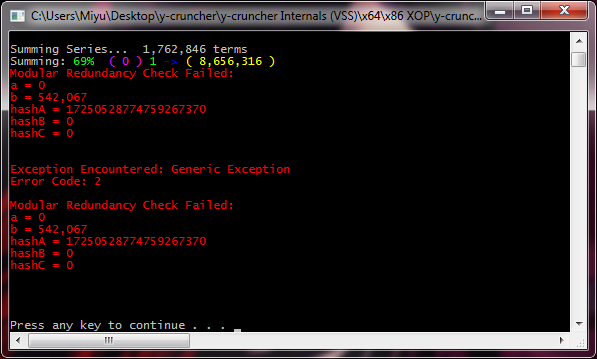
Modular Redundancy Check Failed:
When you see this, it usually means one of three things:
- Memory instability.
- CPU instability.
- An undetected buffer-overrun. (bug in y-cruncher)
Memory instability is by far the most common cause of this.
The modular redundancy check is a very high level of error-checking.
Getting here means that the data passed the lower-level checks. And then got corrupted in memory causing it to fail this high-level check.
CPU instability is possible, but less likely. Cache errors usually cause BSODs instead. But there are parts of a computation where there are no lower-level error checks. So CPU errors in those places will be caught by a high-level check like this one.
And lastly, it is a buffer-overrun in y-cruncher. y-cruncher has checks to detect basic buffer-overruns. But they aren't foolproof. But if this is indeed the case, you will consistently get this failure.
Depending on whether the overrun crosses boundaries into another thread, the hash numbers may differ between runs. But at the very least, you will consistently get a "Modular Redundency Check Failed" in the exact same place. As with all y-cruncher bugs, please let me know so I can fix it.
Starting from v0.6.1, y-cruncher will not attempt to recover from this type of failure. Instead, just quit the program and relaunch it. It will resume from the last checkpoint.
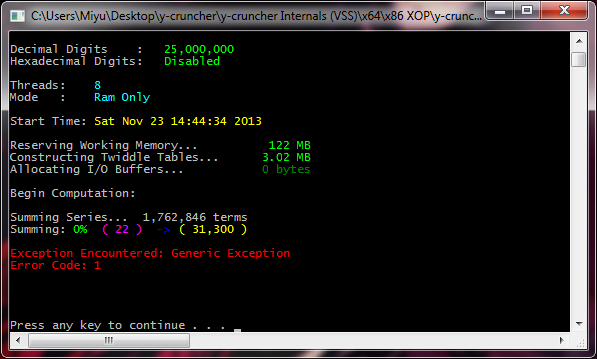
These don't say much other than an error code.
What these error codes mean is not documented at all. Even I don't know them and I need to refer to the source code to see what it is.
The most common of these is error code 1, which means that a large multiplication has failed a sanity check. But that isn't particular useful since almost everything is a large multiplication.
These can be caused by anything. So be ready to suspect everything.
- If it's reproducible, then it's probably a bug in y-cruncher.
- If not, then start checking your hardware. It can be CPU, memory, anything... good luck.
In most cases, y-cruncher will not attempt to correct for such an error. So just kill the program and relaunch it. Checkpoint-restart is kind of the "catch all" for errors.
We're not talking about the occasional read error or CRC fail. What do you do when the entire drive just dies on you?
Well... y-cruncher has no forward error-correction aside from the clunky (and incomplete) RAID3 implementation. So the only thing you can really do is to prepare ahead of time. Make backups of the checkpoints!
Such backups need to be done manually. y-cruncher currently has no fully built-in system to automate it.
- Stop the program. Just close it.
- Go to each of the swap paths and you will find that all the files will be in a folder named, "ycs-00-0" of some sort. The numbers will be unique among all the paths. So copy all those swap folders to a backup. If you open up these folders, you will find swap files with different names. The only ones that y-cruncher needs are the ones with the word, "checkpoint" in them. Everything else can be thrown out. (And you probably will want to do that since they eat up a lot of space.)
- Copy the "y-cruncher Checkpoint File.txt" to the backup as well.
- Make sure the backup is disconnected only when it's safe to do so. y-cruncher has no protection against incomplete copying of swap files. So you want to make sure the disk buffers are flushed before you disconnect anything.
- When you're done making the backup, just rerun y-cruncher. It will pick up from the last checkpoint.
It's useful to "learn" where y-cruncher does its checkpoints. That way you can close it just after a checkpoint to reduce the amount of computation that's wasted.
Restoring from a backup is as simple as copying all the swap files back to the original locations. If you replaced any drives, just set the drive letter(s) to the same as before. Re-running the program will resume the computation as usual. y-cruncher doesn't know (and doesn't care) that you even replaced a drive.
Recent versions of y-cruncher can run a user-supplied script to fully automate the backups.
y-cruncher has tons of other sanity checks not mentioned here. Most of them are related to computational failures. And in such cases, try to reproduce it. That will determine whether or not it's a software or hardware issue.
In some cases, the program will automatically attempt to recover from the error. But these aren't reliable and memory corruption can lead to repeated failures (infinite loops of retries). As with all cases, the best course of action is just to kill the app and rely on the nuclear option of checkpoint restart.
When hardware becomes unstable, expect anything. In most cases, they are easy identify because hardware errors are almost always intermittent. This distiguishes them from bugs in y-cruncher which are mostly deterministic.
But consistent hardware errors are possible and I've seen them happen before. There was a case where an unstable I/O controller caused a computation to end 3 times with exactly the same (incorrect) results. Assuming it was a bug in the program, I spent days trying to trace it down. But after a while, those (consistent) errors became not so consistent. When I ran the exact same computation on another computer with the exact same settings, the results were always correct. After switching around the hard drives on the original computer, the errors went away completely...
Undetected Errors and Failed Computations:
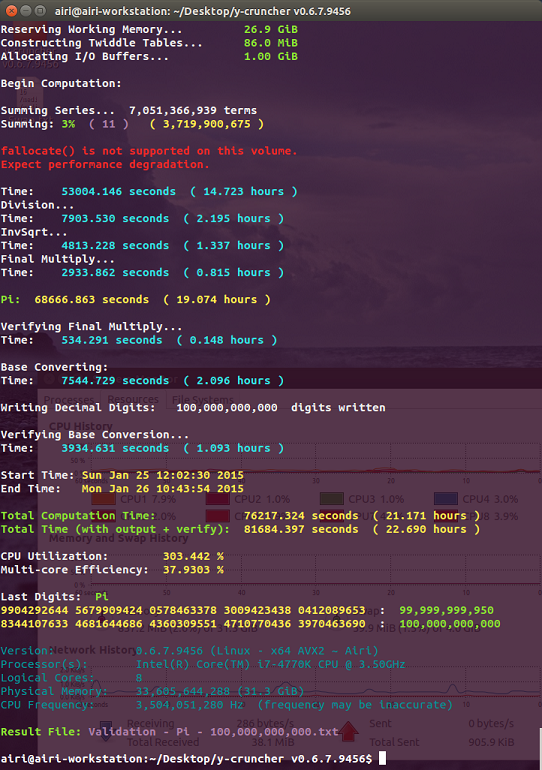 |
| A failed computation of Pi to 100 billion digits. The digits are wrong. This failure is believed to be caused by an undetected SATA transfer error. |
The point of this section is not to scare anyone, but to shed some light on the reality of running large computations as well as some of the unsolved problems in the y-cruncher project.
y-cruncher has a lot of safeguards that will interrupt a computation the moment that things go bad. But unfortunately, it isn't full-proof. While it's uncommon, it is possible for a computation to finish with the wrong result. This is the reason why world records need to be verified using two separate formulas.
To the right is a screenshot of a failed computation of Pi to 100 billion digits. It was one of several such failures that delayed the launch of v0.6.7.
The program gave no errors during the computation, yet the digits were incorrect. The same computation using the exact same settings succeeded a few days later after removing a video card and reformatting all the hard drives.
Needless to say, such failures are the worst thing that can happen. Since you've wasted all this time to get a bad result. And you have no idea what caused the bad result.
Historically, the cause of such failures have been split evenly between hardware instability and software bugs in y-cruncher:
- When the fault is a bug in y-cruncher, it usually is an integer overflow of some underlying datatype.
- When the fault is hardware instability, it's usually disk I/O related.
Bugs in y-cruncher tend to be reproducible and can be fixed. So while it's a problem, it's something that can be dealt with.
In the past, silent disk I/O errors were the biggest problem for y-cruncher. Unless a silent I/O error manages to trigger a higher level redundancy check, it will stay undetected and propagate to the end of the computation with the wrong digits.
However, v0.7.8's addition of the new Disk Raid 0 implementation may have solved this by means of the built-in checksumming which will check for data integrity on every read/write to/from disk. While this system won't fix a bad checkpoint, it will let the user know that a checkpoint is bad and they should cancel the computation or reload a backup of a previous checkpoint.
Alternatively, one can use filesystems like ZFS which are designed for data integrity at the cost of performance.
A Note About Solid State Drives (SSDs)
(This section was written in 2016 and is probably out-of-date. See StorageReview's computation of 100 trillion digits of Pi.)
Solid State Drives (SSDs) are faster alternatives to hard drives both in bandwidth and seek latency. However, they come with two severe drawbacks:
- The price per byte is much higher than hard drives. And you will need a lot of them for large computations.
- They have a limited number of writes due to the nature of flash storage.
Size and Pricing:
The world record for Pi currently stands at 13.3 trillion digits. A logical "next step" would be 20 trillion digits.
Using y-cruncher, 20 trillion digits of Pi would require around 86 - 100 TiB of storage depending on the settings. And that doesn't include backups and digit output.
As of 2016, the largest (reasonably priced) hard drives are around 8 TB for about $250 each. So 16 of them will suffice for about $4,000 USD.
But if you were to go the SSD route, the largest SSDs are around 2 TB in size at around $650. You'll need about 50 of them for over $32,000 USD! And that doesn't include the SATA controllers that would be needed to provide those 50 ports. The bright side is that 50 SSDs will be absurdly fast. So if you have powerful processor(s) to complement the SSDs, you won't have to wait very long to get those 20 trillion digits.
Endurance:
SSD technology has certainly matured enough where they will last decades under "normal use". But y-cruncher is not "normal use". It will put the devices that it runs on under near continuous load 24/7 for as long as the computation is still running.
Let's run some numbers. As of 2016, a typical consumer SSD has the following specs:
- Size: 500 GB
- Sequential Bandwidth over SATA3: 500 MB/s
- Program-Erase (P/E) cycles: 5000
- Write Amplification: 2x
These numbers are leaning towards the optimistic side. Most consumer SSDs are rated for far fewer than 5000 P/E cycles. But in practice, they will last much longer than that provided that the firmware doesn't intentionally brick the device once the limit is reached. We also assume a write amplification of only 2x since y-cruncher's workloads consists of mostly sequential access on a relatively empty drive. Even through y-cruncher will require about 100 TiB of storage to run 20 trillion digits of Pi, the usage will usually be less than half of that. It's only the "spikes" in usage that will reach the full storage requirement.
In a typical y-cruncher computation, the amount of reads and writes are about the same (with slightly more reads than writes). Assuming that the computation is I/O bound, it will be doing disk I/O around 80 - 95% of the time at full bandwidth. To be on the safe-side, let's assume it to be 100%. So the SSD will be sustaining about half the full write bandwidth.
With these assumptions, let's calculate how long the 500 GB SSD will last:
Writes Until Failure = (500 GB) * (5000 P/E cycles) / (2x write amplification) = 1,250,000 GB = 1.25 PB
Time to Failure = (1.25 PB) / (500 MB/s) / (1/2 portion of time doing writes) = 5,000,000 seconds = 1,389 hours = 58 days
58 days is not a very long time. Given that the last few Pi computations have taken months, it might not even be enough for a single computation. Sure, this calculation wasn't very scientific in that some of the assumptions were hand-wavy. But regardless, it doesn't instill much confidence. Do you really want to burn through that much expensive hardware in such a short amount of time?
In short, consumer SSD technology isn't quite ready for large number computations. Perhaps the enterprise stuff is better, but they're also a lot more expensive.
What's the point of swap mode? Why can't you just use the page file?
The operating system page file swapping policies are optimized for "normal" applications. They perform terribly for specialized programs like y-cruncher. Unfortunately, it is difficult to quantify how much slower because nearly all attempts to run a ram only computation using more memory than is physically available leads to so much thrashing of the pagefile that the system becomes unresponsive. (I call it the, "Thrash of Death".) Typically the only way to recover is to hard shutdown the machine.
Technically, it's possible to wait out the Thrash of Death, but it's not productive to wait for something that could potentially take years to run without any indication of progress. (As mentioned, the system becomes completely unresponsive.) The tests that did finish suggest that a ram only computation using the pagefile will be "orders of magnitude" slower than using the built-in swap mode. Not a surprise at all. A page fault to disk is indeed "orders of magnitude" slower than a cache miss to memory.
Why is the pagefile so bad? Because the memory access patterns in y-cruncher are not disk friendly. y-cruncher's swap mode uses alternate algorithms that are specially designed to be disk friendly. It uses domain-specific knowledge to modify the internal algorithms to sequentialize disk accesses and minimize disk seeks. It also knows what it will be accessing in the future and can properly prefetch them in parallel with on-going computation.
Why can't this be done with pagefile hints? Because it would be more complicated than just doing the disk I/Os manually. Furthermore, there would be no guarantee that it would actually behave as desired. In short, the OS pagefile is a black box that's better not to mess with.
To summarize, y-cruncher wants nothing to do with the OS pagefile. It wants the OS to get hell out of the way and let y-cruncher run unimpeded. Windows is pretty good at allowing this with the right API calls. But not in Linux. Starting from v0.7.1, y-cruncher will try to lock pages in memory to prevent the OS from entering the Thrash of Death.
Why does swap mode require privilege elevation on Windows?
Privilege elevation is needed to work-around a security feature that would otherwise hurt performance. Swap Mode creates large files and writes to them non-sequentially. When you create a new file and write to offset X, Windows will zero the file from the start to X. This zeroing is done for security reasons to prevent the program from reading data that has been leftover from files that have been deleted.
The problem is that this zeroing incurs a huge performance hit - especially when these swap files could be terabytes large. The only way to avoid this zeroing is to use the SetFileValidData() function which requires privilege elevation.
Linux doesn't have this problem since it implicitly uses sparse files.
Where is the option to rebuild a dead drive for RAID 3?
The entire RAID 3 feature fell out of use after the improved checkpointing system was released in v0.6.2.
For that matter, the entire multi-level RAID implementation is a rat's nest. It's still maintained, but no longer developed. So it will remain incomplete.
Legacy Disk RAID 0/3: (Removed in: y-cruncher v0.8.3)
This is the old hybrid RAID 0+3 that has existed since v0.6.1. It has since been completely superceded by the new dedicated RAID 0 and has been removed in v0.8.3.
The hybrid RAID 0/3 is a two-level RAID:
- Layer 0: A single filepath.
- Layer 1: A RAID 0 or RAID 3 array of Layer 0 drives. There is a maximum size of 8 Layer 0 drives.
- Layer 2: A RAID 0 array of Layer 1 drives. There is a maximum size of 64 Layer 1 arrays.
A generic setup would look something like this:
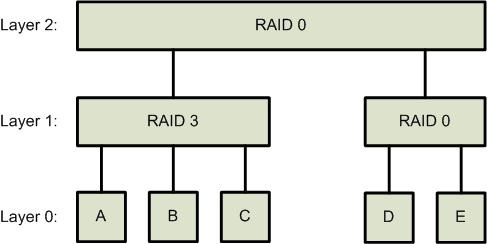
In this example, the configuration can tolerate a failure in any of the drives, A, B, or C. But not in either D or E.
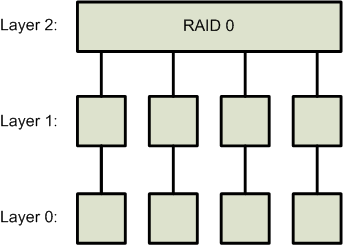
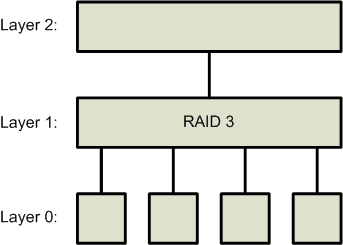
In the past, RAID 0 and RAID 3 setups were implemented as follows:
| RAID 0 | RAID 3 |
 |
 |
The RAID 0/3 was one of the responses to the 10 trillion digits of Pi computation back in 2011. In that computation, over 100 days of time was lost to hard drive failures. The RAID 0 was needed for performance. The RAID 3 was for reliability. But the RAID 3 quickly fell out of use after checkpoint-restart was implemented.