User Guides - Multi-Threading
By Alexander Yee
(Last updated: May 9, 2019)
This guide explains the multi-threading options that were added in y-cruncher v0.6.8 and how they relate to how y-cruncher actually does its parallelization.
While not necessary, it helps to have some basic knowledge of parallel programming paradigms.
Historically, y-cruncher's parallelism is achieved through recursive fork-join of the numerous divide-and-conquer algorithms that it uses. Back in 2008, this type of parallelism was not easy to exploit. Thread worker queues work best with fire-and-forget tasks that require no synchronization. And work-stealing hadn't become mainstream yet. (not that I knew such a thing even existed back then)
In all versions of y-cruncher up through 0.6.7, this recursive fork-join was done by simply spawning a thread at each fork and killing it on join.
While this approach has worked well for so long, it does have its share of problems:
- Creating and destroying threads has a lot of overhead. This was partially solved by limiting the depth of the fork-join recursions.
- With a limited number of tasks, load-balancing became a problem. This was partially solved by static load-balancing. So a lot of non-trivial math was needed to pick parameters that would lead to balanced task trees.
- But static balancing provides no protection against jitter and inherent imbalance such as when the # of processors is not a power of two. (Nearly all the divide-and-conquer algorithms in y-cruncher are binary.)
Fast forward to 2015 and we are finally seeing better tools go mainstream - namely work-stealing frameworks like Cilk Plus. So now it's time to try out these new frameworks and see how they perform.
Past vs. Present:
All versions of y-cruncher up through v0.6.7 exposed a single parameter to the user that controlled how it did multi-threading: "Use N threads".
But in reality, "use N threads" was a complete lie. What it really meant was, "optimize for N logical cores".
y-cruncher never worked with threads for computations. It worked with "tasks" that were run by spawning threads. The "number of threads" that the user would set doesn't actually set the number of threads since this concept never existed in the first place. Instead, it controls the depth of the recursive fork-joining. This led to a number of weird behaviors:
- Sometimes y-cruncher would use double the number of threads that the user specifies. This is because the more "problematic" recursions will recurse one level deeper in an attempt to alleviate load-imbalance.
- When the number of cores is not a power-of-two, y-cruncher would often round up to the next power-of-two.
In y-cruncher v0.6.8, the "threads" parameter has been renamed to "task decomposition" which more precisely describes what it actually does underneath. And a new parameter has been added to choose how to parallelize these tasks. This is a move towards task-oriented parallelism where:
- The program is responsible only for creating independent tasks that can run in parallel.
- The framework is responsible for scheduling and running the independent tasks.
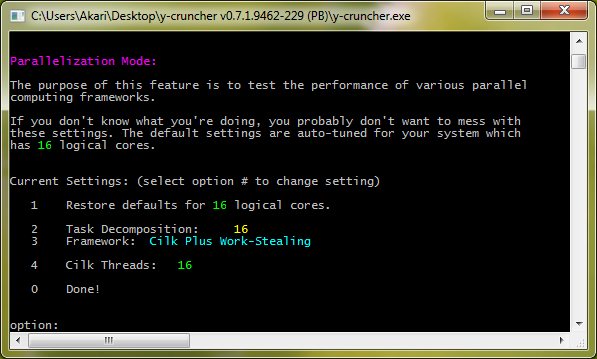
As of v0.7.1, the multi-threading menu lets you specify the following options:
- The amount of task decomposition.
- The parallel computing framework.
- And any sub-options that are specific to the selected framework.
Task Decomposition:
The task decomposition tells the program to decompose the computation into N independent tasks. This number is a suggestion and not a guarantee. y-cruncher may create fewer or more tasks depending on the situation.
A larger task decomposition increases the parallelism potential of the computation and helps with load-balancing. But it also has more computational and memory overhead. Setting the task decomposition equal to the number of logical cores in the system works suitably well for most computations. So this is the default.
But depending on the scenario and the framework that is being used, it may be beneficial to set the task decomposition to be larger than the number of logical cores. In academia, this is called "over-decomposition".
As of v0.7.1, y-cruncher will internally over-decompose up to 2x the specified task decomposition.
The Parallel Computing Framework:
This is the framework that actually does the parallelization. The list of frameworks varies by platform and target binary.
Some frameworks have further options that are specific to the framework.
Below is the set of parallel computing frameworks that y-cruncher supports as of v0.7.7.
None:
Disable multi-threading and sequentialize all the tasks. Use this option if you want to get single-threaded benchmarks.
Setting the framework to "none" is the only way to correctly disable computational-based multi-threading. Setting the task decomposition to 1 by itself is not enough since some subroutines ignore the parameter and will decompose out tasks anyway.
Note that this option only disables parallelism for computation. Disk I/O in swap mode uses a completely separate threading system that is independent of the one used for computation. If you want to force even the disk I/O to be sequentialized, you will need to do this at the operating system level. In Windows, this can be done by using Task Manager to set the processor affinity to one core.
C++11 std::async():
Use C++11 std::async(). What it exactly does is dependent on the compiler and environment.
The launch policy can be set to either:
std::launch::async
std::launch::async | std::launch::deferred
The observed behavior of each policy on each platform is as follows:
Windows/MSVC/ICC Linux/GCC async only Work is dispatched on a thread pool Work is spawned on a new thread. async | deferred Work is deferred and sequentialized. To be clear, async + deferred on Linux doesn't parallelize anything. All tasks are run sequentially, so it's completely useless.
Thread Spawn:
Spawn a new thread for each task and kill it when the task ends.
This is what y-cruncher has historically used from the first version all the way up through v0.6.7. Because of the overhead of repeated creation/destruction of threads, it is not very efficient on small computations where work units tend to be smaller.
- On Windows, it uses WinAPI CreateThread().
- On Linux, it uses POSIX pthread_create()
Windows Thread Pool:
Use the Windows built-in thread pool implementation. This option may create many worker threads - much more than the number of logical cores in the system. But nevertheless, it seems to be very efficient.
The number of threads that the Windows thread pool creates has been observed to be roughly equal to the number concurrent tasks at any given point of a computation. For y-cruncher, this comes out to be 2x the requested task decomposition since y-cruncher internally over-decomposes by 2x.
Despite being a part of Windows, this framework is actually not aware of processor groups. So it will not be able to use more than 64 cores.
Push Pool:
A thread pool that uses decentralized work dispatching. The name comes from the way that work is "pushed" on to idle threads in a manner that is opposite to work-stealing. The framework is new to v0.7.1 and is the first time y-cruncher has hand-rolled its own (non-trivial) framework from ground-up.
There are two configuration settings for this framework:
- The number of threads. (Default: unlimited)
- Enable/disable randomization of thread selection. (Default: enabled)
The number of threads can be either a fixed number or unlimited. If it is a fixed number, the framework will use exactly that many threads and no more. When an unlimited number of threads is specified, the push pool will spawn as many as needed in a manner similar to the Windows thread pool. So the number of threads that will be created is the number of overlapping work-units. (or about 2x the requested task decomposition)
Capping the number of threads seems to cause more problems than it solves. There is little overhead for having excess threads. And the push pool does not behave efficiently when all worker threads are busy and there is no option to spawn more. For this reason, the push pool defaults to unlimited threads.
When randomization is enabled, work that is submitted to the pool will be given to threads at random. This spreads out the work across the threads and reduces the average time needed to find an idle thread. Unfortunately, desktop computers don't have enough cores to see any effect from randomization.
On desktop computers with 8 - 16 logical cores, the push pool (when properly configured) is often better than all other frameworks on this page. It remains to be seen how well it scales onto larger systems.
This framework is aware of processor groups for binaries that target Windows 7 or later. So it will be able to utilize more than 64 logical cores.
Cilk Plus Work-Stealing:
Use Cilk Plus. It is a work-stealing framework that is designed specifically for the fork-join parallelism that y-cruncher uses.
When used in conjunction with over-decomposition, Cilk Plus can achieve a CPU utilization that is higher than any of the other frameworks. Unfortunately, it also has the most overhead. So in many cases, Cilk Plus ends up being slower than most of the other frameworks.
Cilk Plus isn't always available. On Linux, it is only available for the dynamically linked binaries. On Windows, it is available only to the AVX and AVX2 binaries. It is not available to the rest of the Windows binaries since they were compiled with the Microsoft compiler which does not support Cilk Plus.
This framework is aware of processor groups. So it will be able to utilize more than 64 logical cores on Windows.
Intel has deprecated Cilk Plus in favor of Thread Building Blocks (TBB). So Cilk Plus will eventually be removed from y-cruncher.
Thread Building Blocks (TBB):
Use Thread Building Blocks. It's a more general parallel programming library which will supercede Cilk Plus.
Like Cilk Plus, TBB isn't always available for y-cruncher. It is available only for the 64-bit Windows binaries and is not available in any of the Linux binaries yet. Support for TBB in Linux is waiting for GCC to pick up built-in compiler support - which looks unlikely at this point.
Version v0.7.8 will add TBB support for the dynamically linked Linux binaries.
Windows:
On Windows, std::async() and the Windows thread pool are indistinguishable in performance. It's very likely that the Microsoft and Intel compilers actually use the Windows thread pool to implement std::async().
The push pool is slightly better than the Windows thread pool for desktop systems. (usually about 1 - 2% for Pi computations) On larger systems with more cores, the opposite seems to be true. But there currently isn't enough data to definitively say which is better.
Cilk Plus has too much overhead. So it's usually worse than everything else except for the "None" framework.
On systems with more than 64 logical cores and multiple processor groups, things are different. The push pool with randomization suffers from load imbalance. Cilk Plus does better, but it has a bug that may cause an imbalance in the thread assignments to each processor group. The push pool with randomization disabled seems to do fairly well.
The push pool with unlimited threads and randomization enabled is the default for Windows when there is only one processor group. When there are multiple processor groups, Cilk Plus is the default if it is available.
TBB hasn't been well analyzed yet. So y-cruncher will never pick it as a default. Initial tests show that it is neither strictly better nor strictly worse than Cilk Plus. But subsequent larger scale test show that TBB is significantly worse than even Cilk Plus.
Linux:
On Linux everything is bad. I'm not kidding. Everything is bad.
- std::async is the same as thread spawning.
- The Windows thread pool is not available.
- The Push Pool isn't much better than thread spawning.
- Cilk Plus reeks of the same overhead that kills it on Windows.
- Cilk Plus is deprecated and has been removed from GCC.
- GCC doesn't support TBB out-of-box.
Multi-threaded computations on Linux are roughly 5 - 10% slower than on Windows. But single-threaded computations are within 1%. So it's not like the code is slow on Linux. It's just that parallelization simply sucks on Linux for some reason. This is same regardless of whether you're spawning threads or reusing them.
The Push Pool was written with the sole purpose of bringing a thread pool implementation to Linux. But that seemed to have benefited Windows more than Linux.
The exact same Push Pool code that achieves 4.24x speed up on 4 cores + HT on Windows achieves only 4.07x on Linux. The CPU utilization is significantly lower in Linux than in Windows. So far, this situation has resisted all attempts to study it. But everything seems to point at the kernel scheduler.
Overall, the performance gap between Windows and Linux has steadily increased in the past few years. Something in Windows improved drastically between Win7 and Win8 which leads to higher CPU utilization and faster computational throughput. In contrast, Linux actually seems to have regressed. There is a noticable performance drop in parallel performance when upgrading from Ubuntu 15.04 to 15.10.
To rub salt in the wound, GCC has already done away with Cilk Plus without adding TBB as a built-in alternative - thus leaving the compiler with no suitable out-of-the-box parallel computing library.
Scalability:
As of v0.7.1, y-cruncher is coarse-grained paralleled. On shared and uniform memory, the isoefficiency function is estimated to be Θ(p2). This means that every time you double the # of processors, the computation size would need to be 4x larger to achieve the same parallel efficiency.
The Θ(p2) heuristically comes from a non-recursive Bailey's 4-step FFT algorithm using a sqrt(N) reduction factor. In both of the FFT stages, there are only sqrt(N) independent FFTs. Therefore, the parallelism cannot exceed sqrt(N) for a computation of size N.
That said, most of the FFT-based multiply algorithms that were added to y-cruncher after 2012 are able to parallelize recursively into 4-step FFT reductions. So the actual isoefficiency function is probably better than Θ(p2). Whatever the case is, mainstream desktop systems do not have enough cores to explore the asymptotics.
The isoefficiency coefficient of Θ(p2) implies weak scalability, but not strong scalability. Empirical evidence supports this as y-cruncher's parallel speedup is abysmal at small computation sizes, but almost linear at large sizes (when excluding factors like thermal throttling and memory bandwidth limitations).
Non-Uniform Memory:
As of 2018, y-cruncher is still a shared memory program and is not optimized for non-uniform memory (NUMA) systems. So historically, y-cruncher's performance and scalability has always been very poor on NUMA systems. While the scaling is still ok on dual-socket systems, it all goes downhill once you put y-cruncher on anything that is extremely heavily NUMA. (such as quad-socket Opteron systems)
While y-cruncher is not "NUMA optimized", it has been "NUMA aware" since v0.7.3 with the addition of node-interleaving memory allocators.
These node-interleaving allocators do not solve NUMA problem, but they do alleviate its effects. Node-interleaving is typically supported at the BIOS level as well as in Linux's numactl package, but most people do not use it due to lack of awareness. y-cruncher v0.7.3 attempts to solve this problem automatically by detecting the NUMA topology and manually doing the node interleaving.