12.1 Trillion Digits of Pi
And we're out of disk space...
By Alexander J. Yee & Shigeru Kondo
(Last updated: September 22, 2016)
It's been 2 years since our last computation and it didn't look like anyone else was attempting to beat it. So we thought we'd see how much better we could do with improved software and two extra years of Moore's Law on computer hardware.
We didn't go for 20 trillion digits because of the massive space requirements. Instead we went for a "small and fast" computation of only 12.1 trillion digits.
More digits can be found here: http://piworld.calico.jp/estart.html |
|
.jpg)
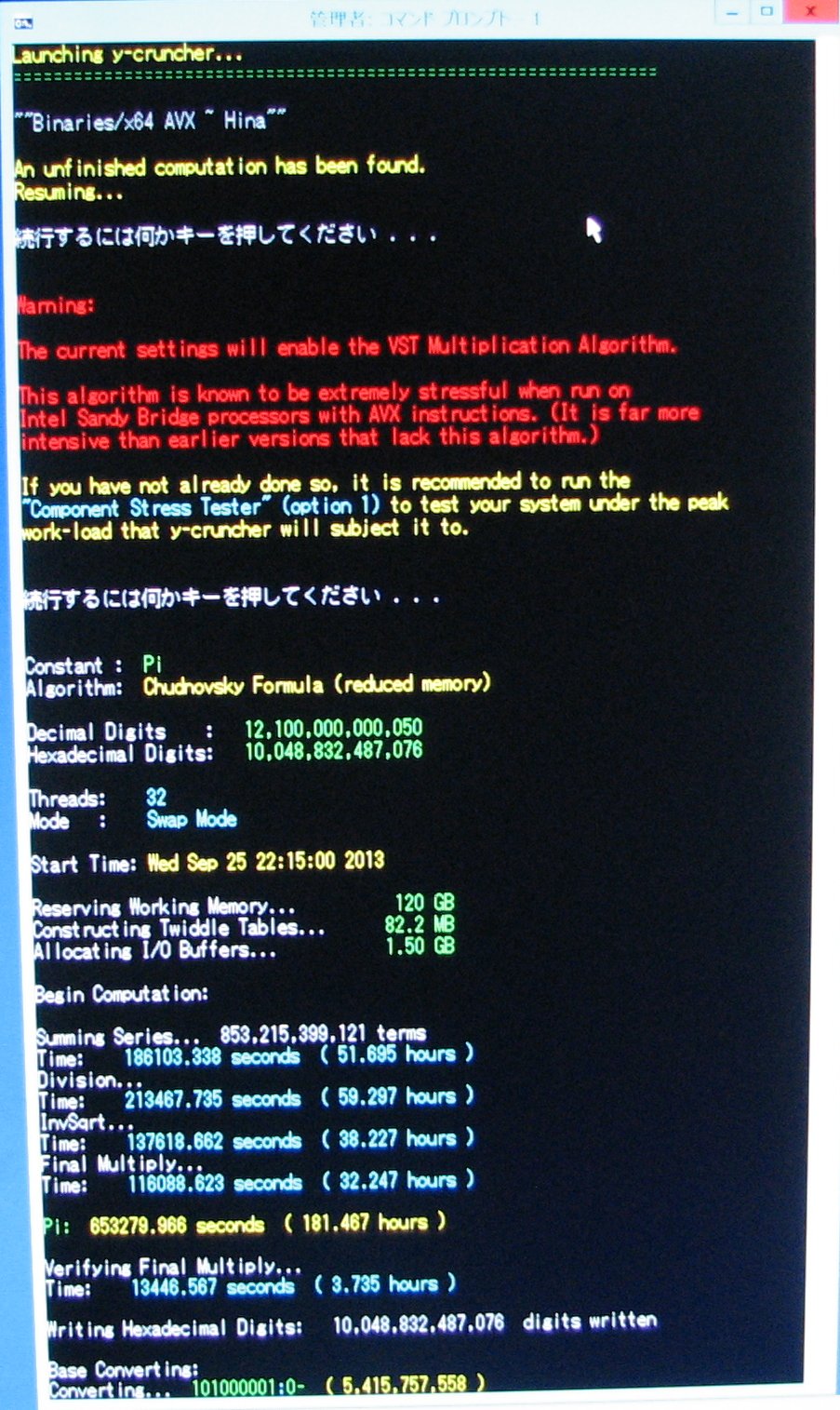
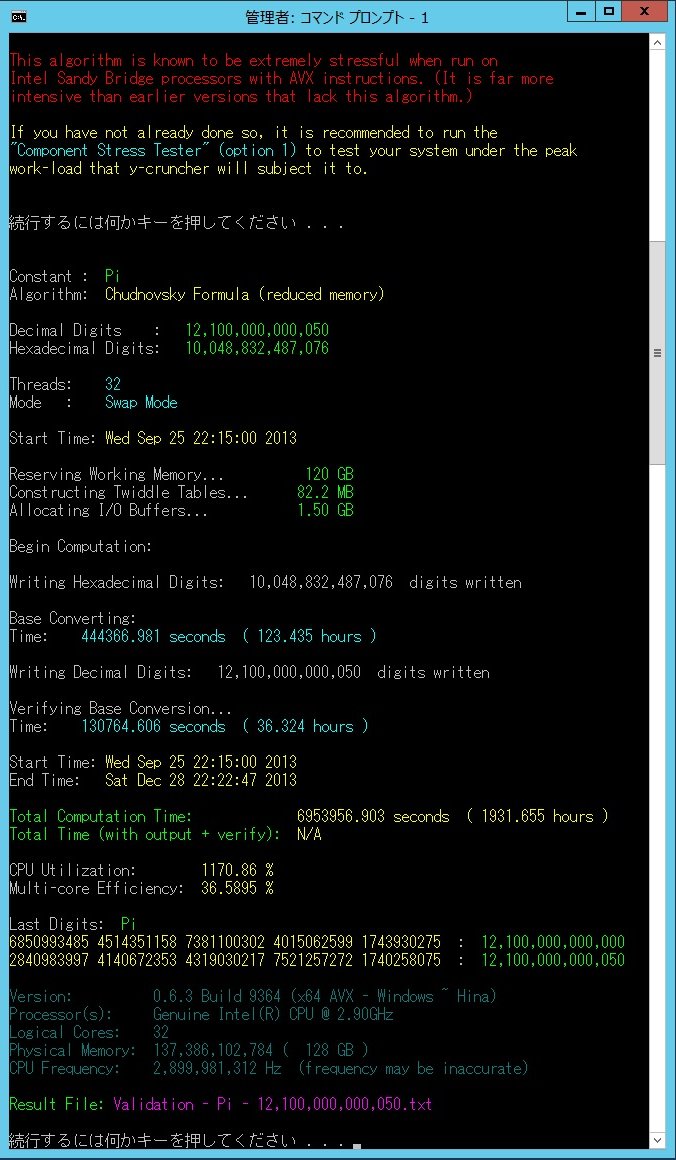
Computation Statistics - All times are Japan Standard Time (JST).
Unlike the grueling 371 days that was needed for our previous computation of 10 trilllion digits, this time we were able to beat it in about 94 days.
The computation was interrupted 5 times - all due to hard drive errors. Furthermore, a bug was discovered in the software which had to be fixed before the computation could be continued.
Memory Statistics:
- 60.2 TiB of disk was needed to perform the computation.
- 9.20 TiB of disk was needed to store the compressed digit output.
- More disk space was needed to make backups of the checkpoints.
TiB = 240 bytes
Computation Statistics:
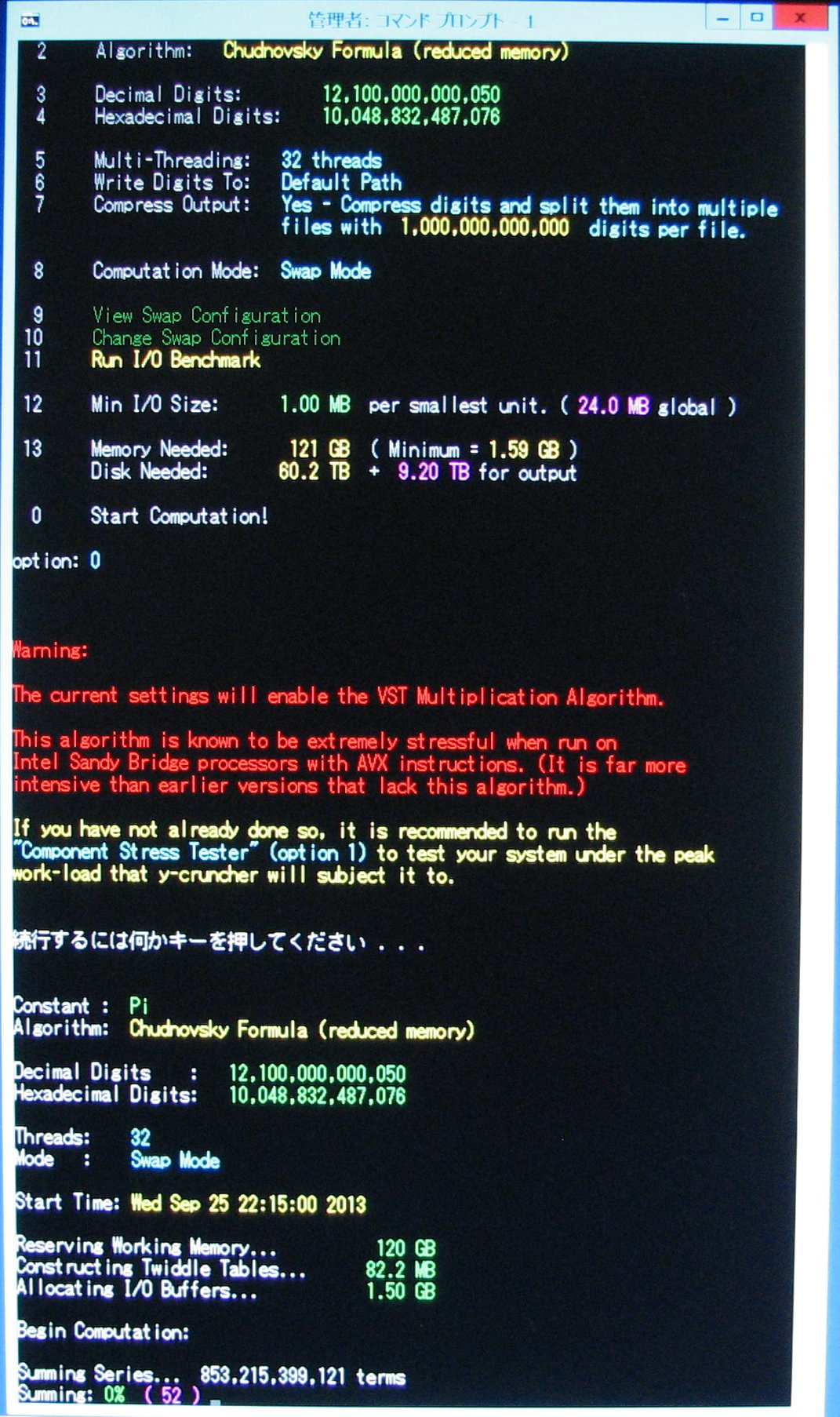
- Algorithm: Chudnovsky Formula
- Time: 94 days
- Start: 10:15 PM (JST), September 25, 2013
- End: 10:23 PM (JST), December 28, 2013
- Validation File/Event Log
Verification Statistics:
- Algorithm: Bellard's BBP
- Time: 46 hours
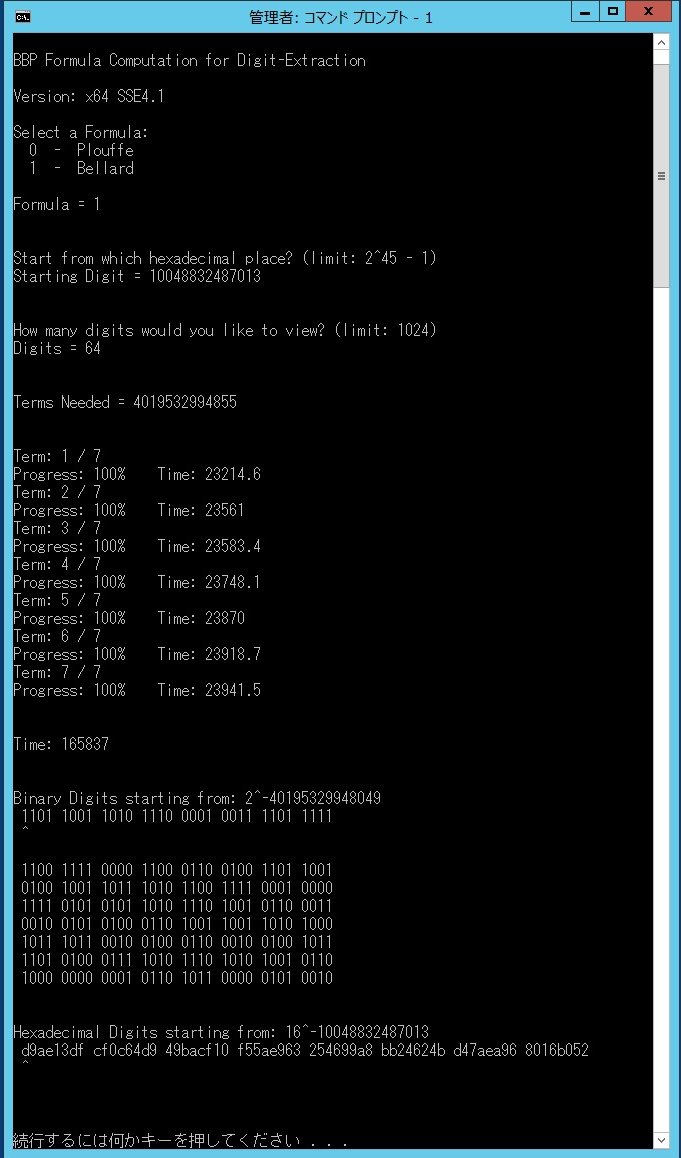{kind=link}
| Computation Step | Time |
Series Summation: |
75 days |
Division: |
59 hours |
Square Root: |
38 hours |
Final Multiply: |
32 hours |
Verify Multiply: |
3.74 hours |
Base Conversion: |
123 hours |
Verify Base Conversion: |
36 hours |
Output Digits: |
56 hours |
| Time Lost to HW Failures: | 12 days |
| Total Computation Time: | 82 days |
| Total Real Time: | 94 days |
As with the previous computations, Shigeru Kondo built and maintained the hardware. This time he had a new machine based on the Intel Sandy Bridge processor line.
Processor: |
2 x Intel Xeon E5-2690 @ 2.9 GHz - (16 physical cores, 32 hyperthreaded) |
Memory: |
128 GB DDR3 @ 1600 MHz - 8 x 16 GB - 8 channels) |
Motherboard: |
Asus Z9PE-D8 |
Hard Drives: |
Boot: 1 TB Pi Output: 4 x 3 TB Computation: 24 x 3 TB Backup: 4 x 3 TB |
Operating System: |
Windows Server 2012 x64 |
And of course the obligatory pictures... (click to enlarge)
 |
 |
||
 |
 |
 |
 |
| Close up of the motherboard. | SATA Controllers | Hard Drive Rack | Hard Drive Fans |
The math and overall methods were the same as our previous computations:
- The computation was done using the Chudnovsky formula.
- The verification was done using the BBP formulas.
- Modular hash checks were used to verify the final multiply and the radix conversion.
The hexadecimal digits of the main computation matched that of the BBP formula:
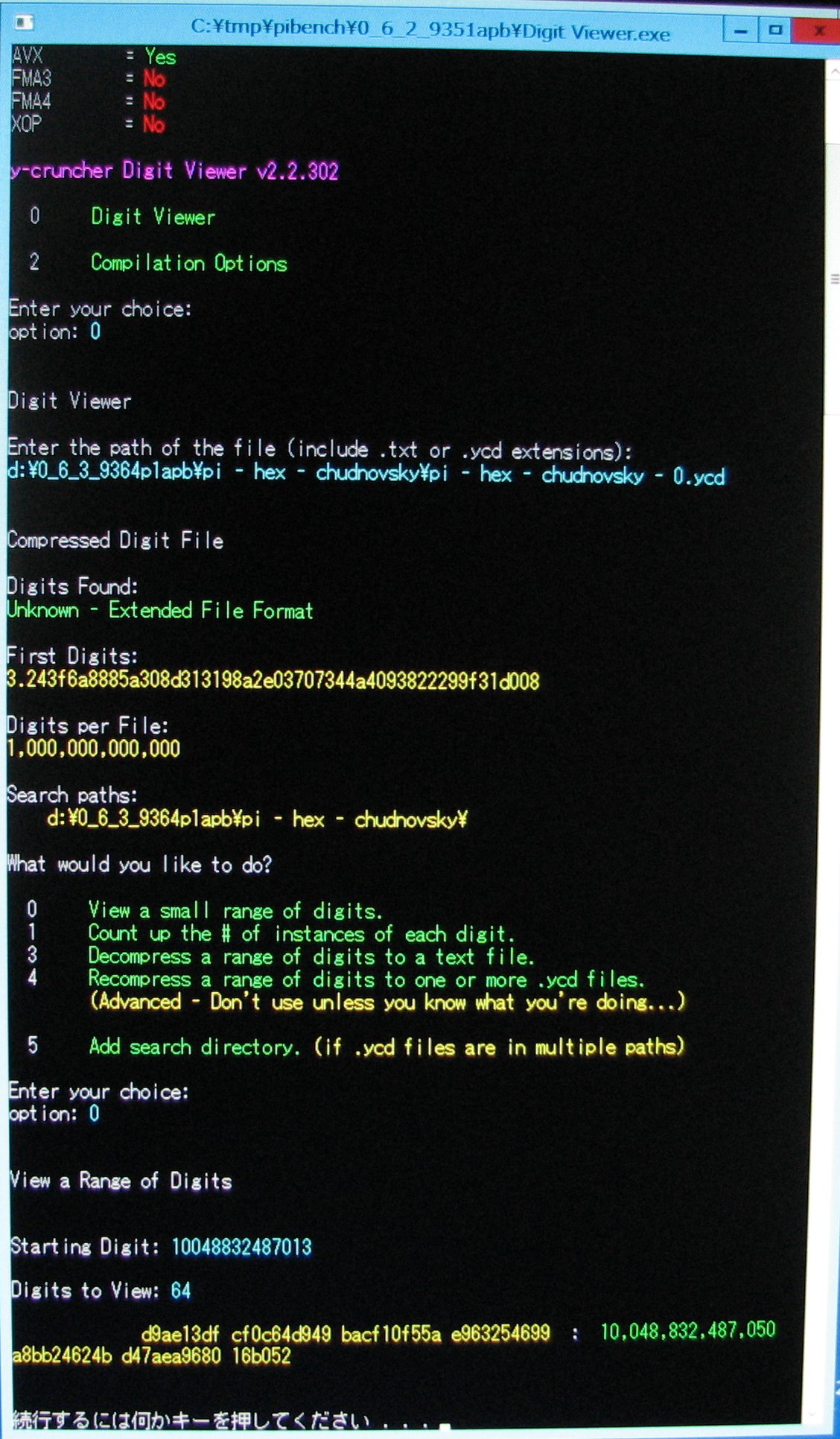{kind=link}
The main computation was done using a new version of y-cruncher (version v0.6.2). The verification was done using the same BBP program from before.
Our previous computation of 10 trillion digits required 371 days. This time we were able to achieve 12.1 trillion digits in "only" 94 days. So it comes out to about 5x improvement in computational speed - which is a lot for only 2 years... (way ahead of Moore's Law)
The reason for this was a combination of several things:
- Better Hardware: 12 core Westmere -> 16 core Sandy Bridge.
- Much improved fault-tolerance in the software. 180 days -> 12 days lost to hardware failures.
- Numerous performance optimizations to the software.
Improved Fault-Tolerance:
Fault-tolerance is the most obvious improvement. A factor of 2 comes from just eliminating the impact of hard drive failures.
The key is the checkpoint-restart. This is the ability to save the state of the computation so that it can be resumed later if the computation gets interrupted.
y-cruncher has had checkpoint-restart capability since v0.5.4 where it was added specifically for our 5 trillion digit computation. But this original implementation turned out to be horrifically insufficient for the 10 trillion digit run.
The problem was that it only supported a linear computational model and thus restricted a computation a small number of checkpoints. The longer the computation, the longer the time between the checkpoints. In the 10 trillion computation, some of the checkpoints were as spread out as 6 weeks apart.
Meaning that: In order to make progress, the program had to run uninterrupted for up to 6 weeks at a time.
While it's easy to keep a computer running for 6 weeks, the MTBF of the 24 hard drive array was only about 2 weeks. And when the MTBF becomes shorter than the work unit, bad things happen. You basically get a downward spiral in efficiency. And this hit us hard: Several of the largest work units required many attempts to get through. Ultimately, it was basically a disaster since it nearly doubled the time needed to compute 10 trillion digits of Pi.
y-cruncher v0.6.2 solves this problem by completely rewriting and redesigning the checkpoint-restart system to allow for finer-grained checkpointing. This was done by adding the ability to save and restore the execution stack. The result is that those 6-week long gaps were reduced to a mere hours - or at most a few days. This boost in reliability enabled us to sail through the 12.1 trillion digit computation without too many issues.
In this computation, there were 5 hard drive failures - 4 of which wasted very little computation time. The 5th and last failure happened during the verification of the radix conversion. The radix conversion lacks checkpoints due to the in-place nature of the algorithm. So this final failure added about a week to the time that was lost.
There were a total of about 12 days with no useful computational work. This includes the time lost to hard drive failures as well as the time used to perform preemptive backups of the checkpoints.
Performance Optimizations:
If we assume that the fault-tolerance accounts for 2x of the 5x improvement, then the remaining 2.5x is from performance improvements.
The new version of y-cruncher adds a lot of performance enhancements. But it's difficult to quantize it since we also had better hardware.
A partial list of the improvments in y-cruncher v0.6.2 are:
- Native implementation for Newton's Method Division. Prior to v0.6.x, division was done as a separated reciprocal + multiply.
- Division, Square Roots, and Radix Conversions now use Middle-Product with wrap-around convolution.
- Redundant FFT transforms are now reused whenever possible.
- A new multiplication algorithm that performs better for extremely large products.
- A new software RAID implementation that reduces the cost of seeks.
The most interesting and unexpected of these is likely the last one. So that's the only one we will go into detail.
What did it do? It basically halved the amount of disk I/O needed to perform multiplications larger than 1 trillion digits. This improvement was completely unexpected and was a shocking (and pleasant) surprise to see for the first time. At these large sizes, the computation is largely bound by disk I/O. So any improvements to disk access translates directly to performance gain.
y-cruncher has always had a built-in software RAID. But version 0.6.1 does away with the old implementation and replaces it with a new (and overly elaborate) one that has native support for gather and scatter operations. (among other improvements)
The out-of-core FFT algorithm for large multiplication has non-sequential disk access. Normally, this algorithm can do a forward and inverse transform using only 3 passes over the dataset. This is known as the "3-step" algorithm. However, the larger the FFT, the more non-sequential the disk access becomes. At some point, the access disk access becomes so non-sequential that the run-time becomes dominated by seeks rather than reads or writes. This is a run-away effect. The number of disk seeks increases quadratically with the size of the FFT. So at some point, it becomes better to switch to the "5-step" algorithm which has fewer disk seeks, but needs nearly double the amount of disk access (in bytes).
In our 5 and 10 trillion digit computations, the threshold where we switched to the 5-step algorithm was approximately 1 trillion digits. So all multiplications above 1 trillion digits had to pay a penalty of 2x in the disk I/O. In the 12.1 trillion digit computation, this threshold was increased to 10 trillion. How did that happen?
- The old version of the RAID had no gather/scatter support. So when an FFT invokes a series of non-sequential disk accesses, each block is processed one-by-one. All the disks need to be synchronized after each contiguous block. (The call blocks the computation until all the disks have finished that block.) This approach suffers heavily from "straggling" seeks that take longer than normal.
- In the new version, these non-sequential accesses are passed directly to the RAID through the gather/scatter interface. Each disk independently operates on its own portion of each block. There is no synchronization until the very end - when the entire gather/scatter operation is done. This eliminates the effect of the "straggling" seeks that take longer than usual.
Based on emperical evidence, this new approach reduces the cost of seeks by about factor of 2 - 4. The improvement increases with the number of drives.
Because the cost of seeking had dropped so dramatically, it allowed the program to be more aggressive with using the 3-step algorithm. This ultimately increased the cross-over threshold of the 3-step and 5-step algorithms to 10 trillion digits.
Nevertheless, this speedup didn't come without a cost. The new RAID system was one of the most difficult and time-consuming components to implement and test.
Our 5 trillion digit computation had virtually no issues. There was one CPU or memory error early on. But nothing big.
But our 10 trillion digit computation was plagued with hard drive failures. These were so bad that it nearly doubled the time needed for the computation.
For this 12.1 trillion digit computation, we fixed or worked around all of these issues. But when you get rid of existing bottlenecks, you expose new ones...
This time, the new bottleneck is disk capacity.
A 20 trillion digit computation of Pi would need a lot of disk space. Using y-cruncher v0.6.3, it would require:
- 111 TiB of disk for the computation (or 102 TiB using a special "Reduced Memory" mode)
- 15.2 TiB to store the compressed digits
- 27 TiB of storage to backup the checkpoints
Even with the largest drives available (4 TB), it would have required a prohibitively large number of drives. While it's theoretically possible to have over 100 drives hooked up to a single motherboard, there is a point where it becomes... insane - even if you forget about cost. And if the MTBF drops below a few days, then you'll run into the same run-away time loss from hard drive failures. Getting around this would require stacking even more redundancy which further increases the capacity requirement. In any case, there's a limit somewhere.
It's possible to decrease the memory requirement at the cost of performance. But it cannot be reduced by more than a factor of two before the performance drop becomes a run-away effect. So beyond that, new math will be needed to develop algorithms that use even less memory.
In other words: Computing Pi on commodity hardware is nearing the point where it is at the mercy of Moore's Law for storage capacity.
- Computational power is not the limiting factor. So there's no need to use GPUs.
- Reliability isn't much of a problem since it can largely be worked around with software.
But there's not much that can be done about storage (other than to get more of it). Random binary data doesn't compress very well either...
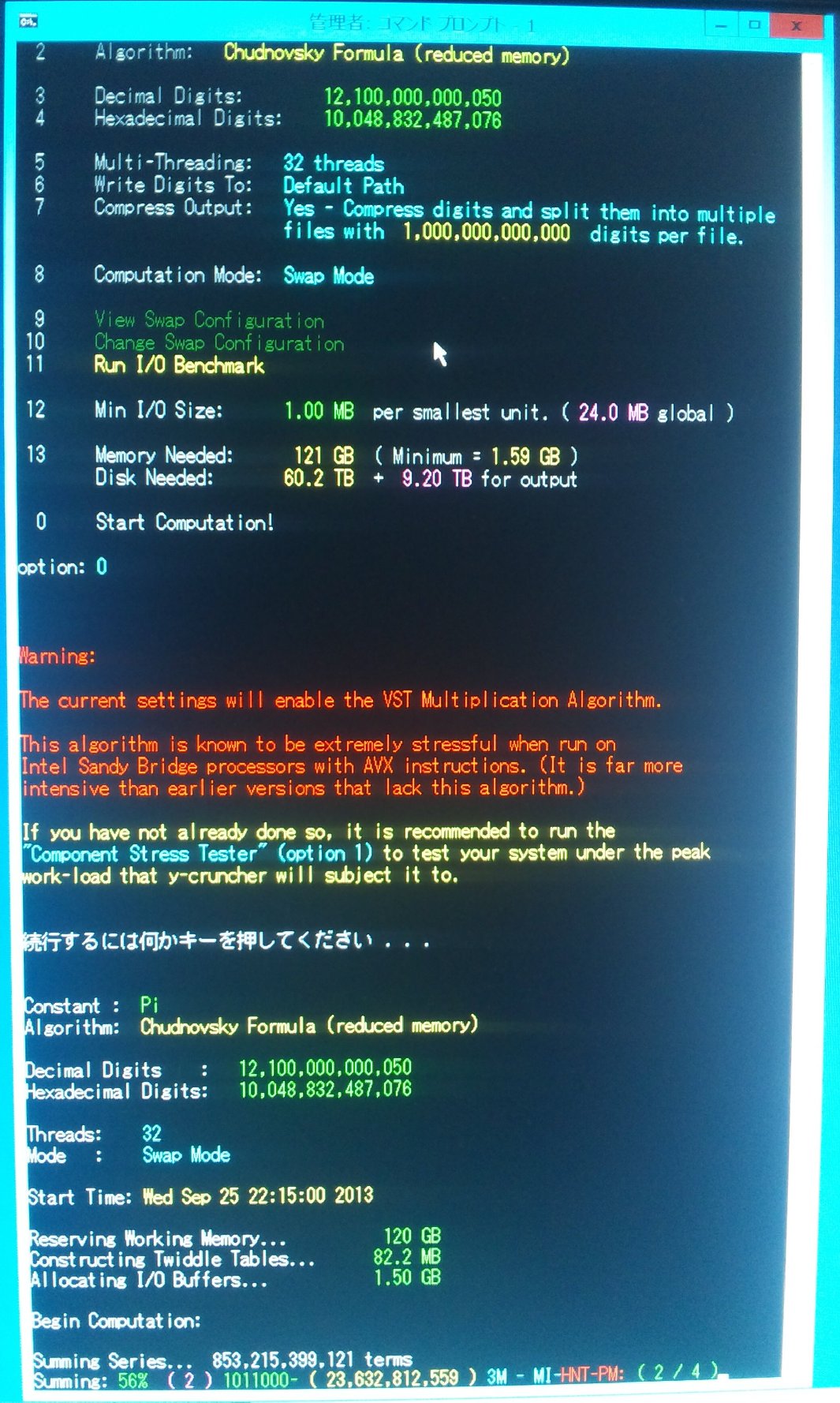
| Date | Event | Screenshot |
| September 25, 2013 | Start of Computation |
View |
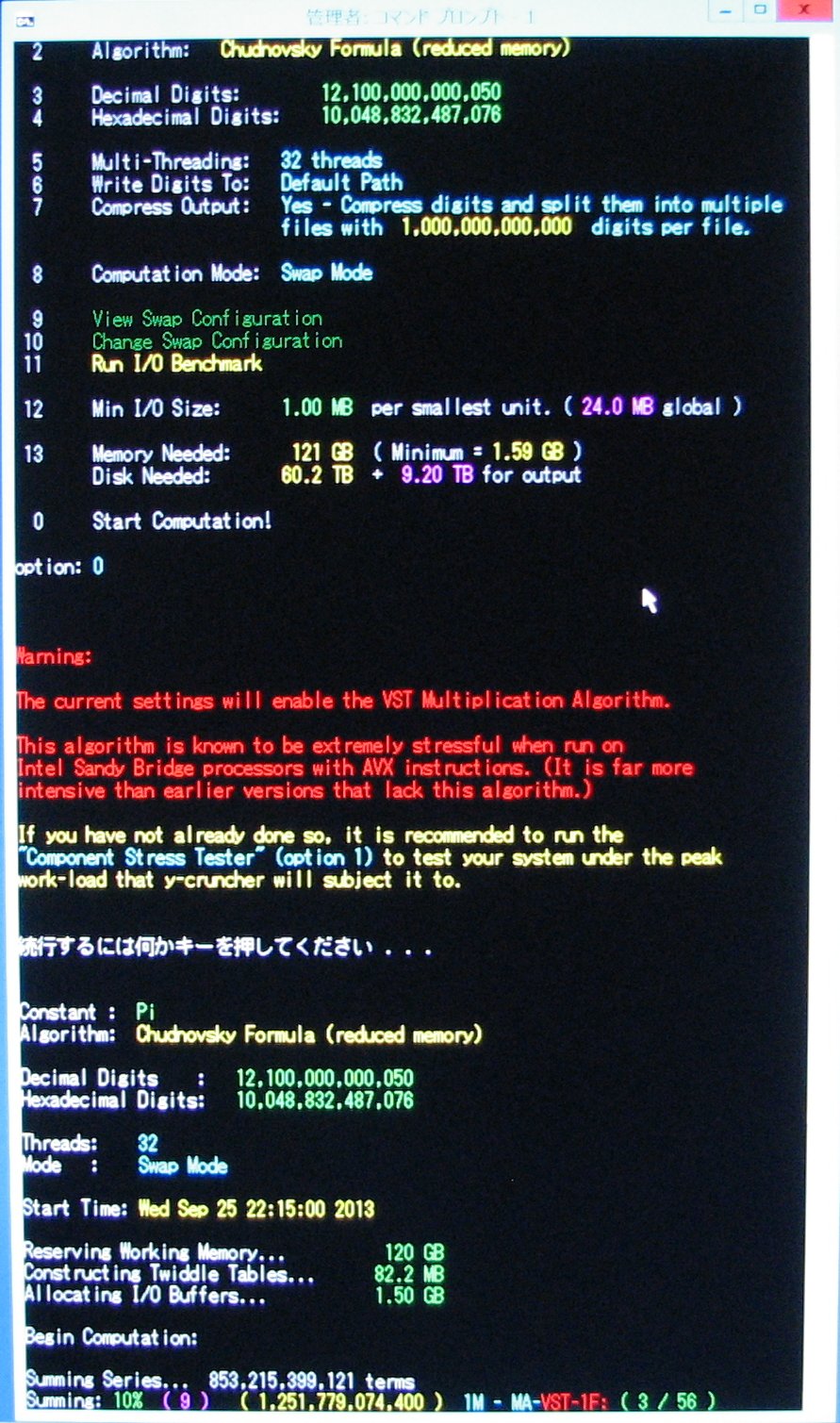
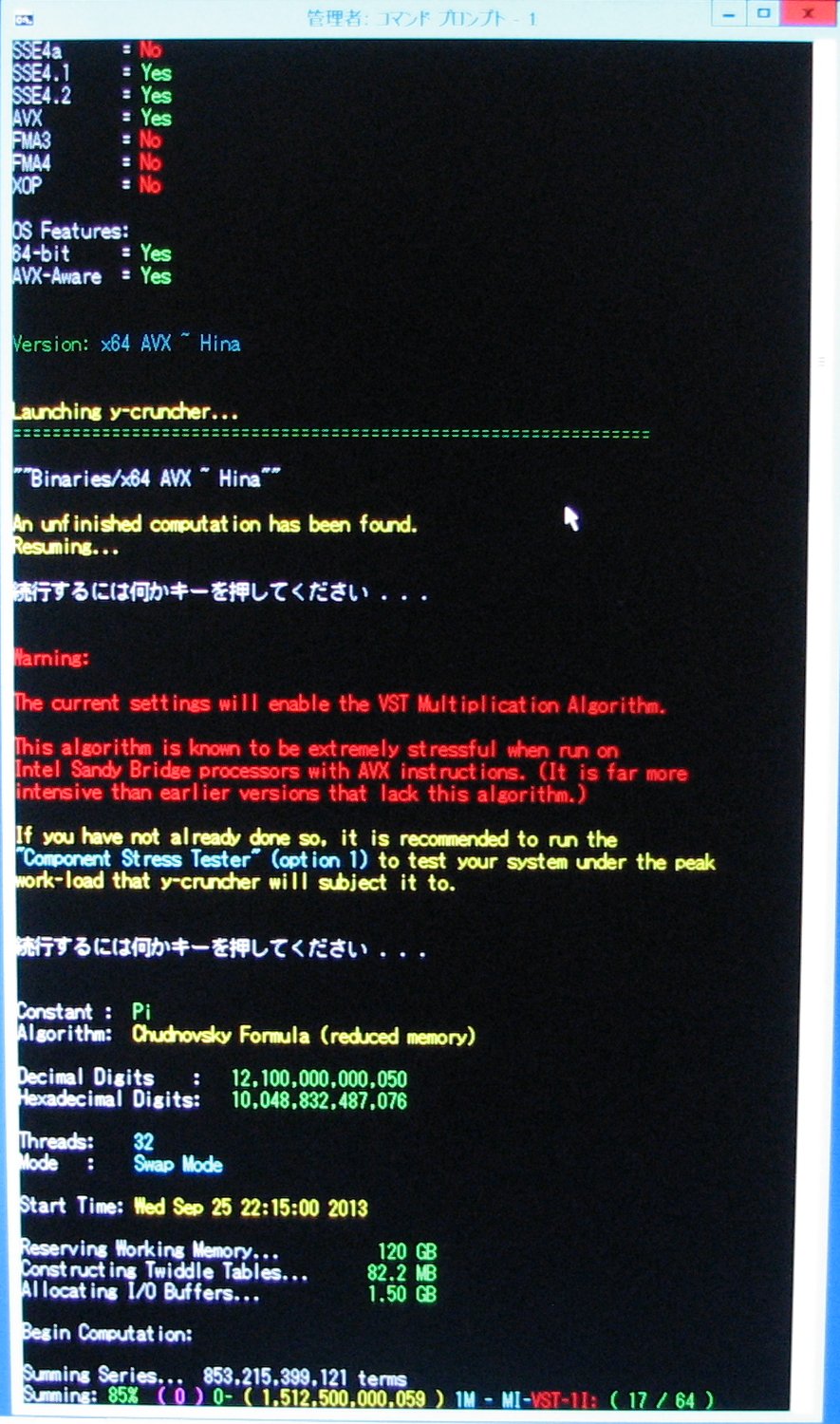
| October 1, 2013 | Series summation is 10% complete. |
|
| October 2, 2013 | Week 1: Series summation is past 10% complete. |
View |
| October 3, 2013 | Series summation is 13% complete. |
|
| October 5, 2013 | Series summation is 16% complete. |
|
| October 8, 2013 | Series summation is 21% complete. |
|
| October 9, 2013 | Week 2: Series summation is past 21% complete. |
View |
| October 12, 2013 | Series summation is 27% complete. |
|
| October 16, 2013 | Week 3: Series summation is past 27% complete. |
View |
| October 17, 2013 | Series summation is 34% complete. |
|
| October 23, 2013 | Week 4: Series summation is past 34% complete. |
View |
| October 24, 2013 | Series summation is 44% complete. |
|
| October 30, 2013 | Week 5: Series summation is past 44% complete. |
View |
| November 1, 2013 | Series summation is 56% complete. |
|
| November 6, 2013 | Week 6: Series summation is past 56% complete. |
View |
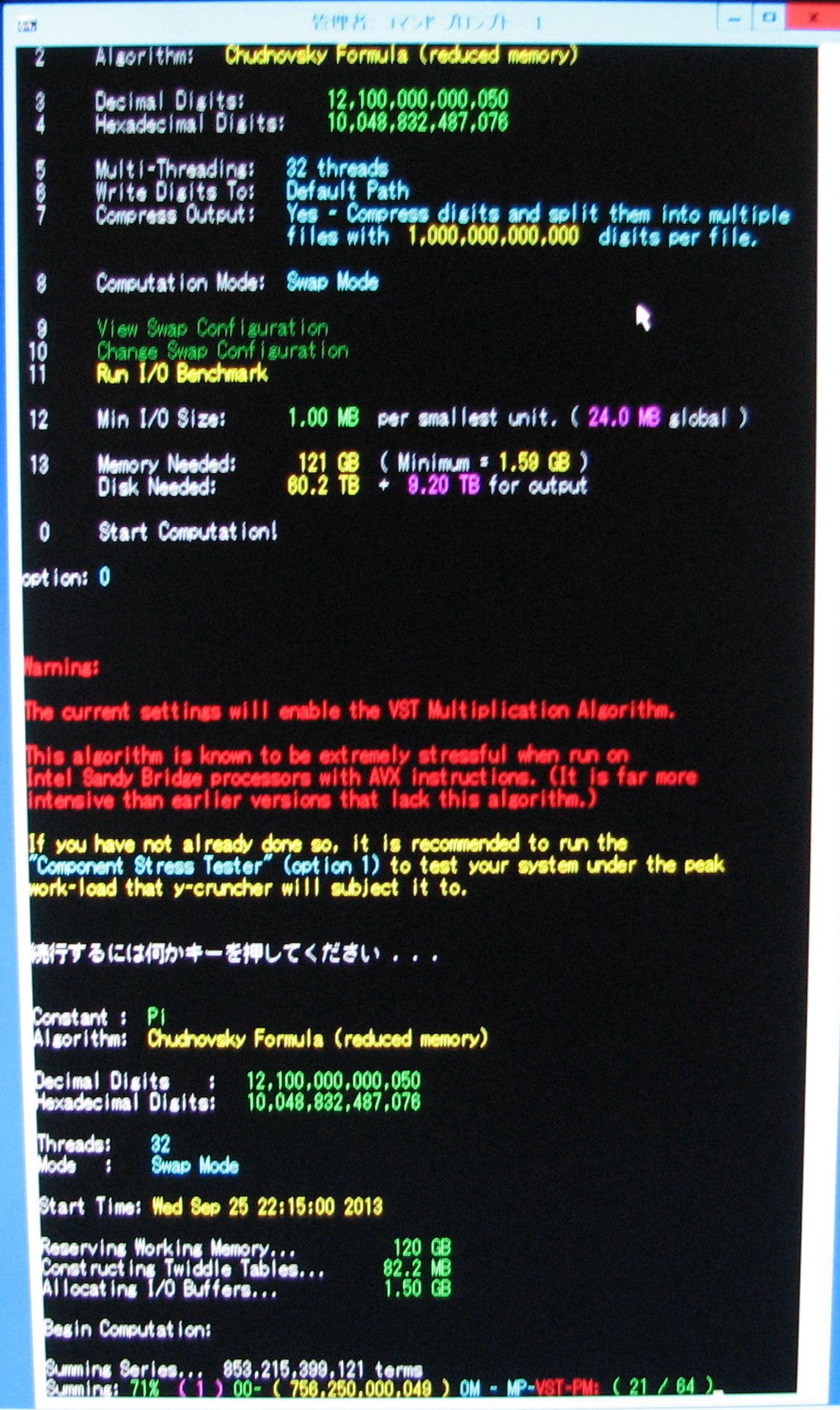
| November 12, 2013 | Series summation is 71% complete. |
|
| November 13, 2013 | Week 7: Series summation is past 71% complete. |
View |
| November 20, 2013 | Week 8: Series summation is still past 71% complete. |
View |
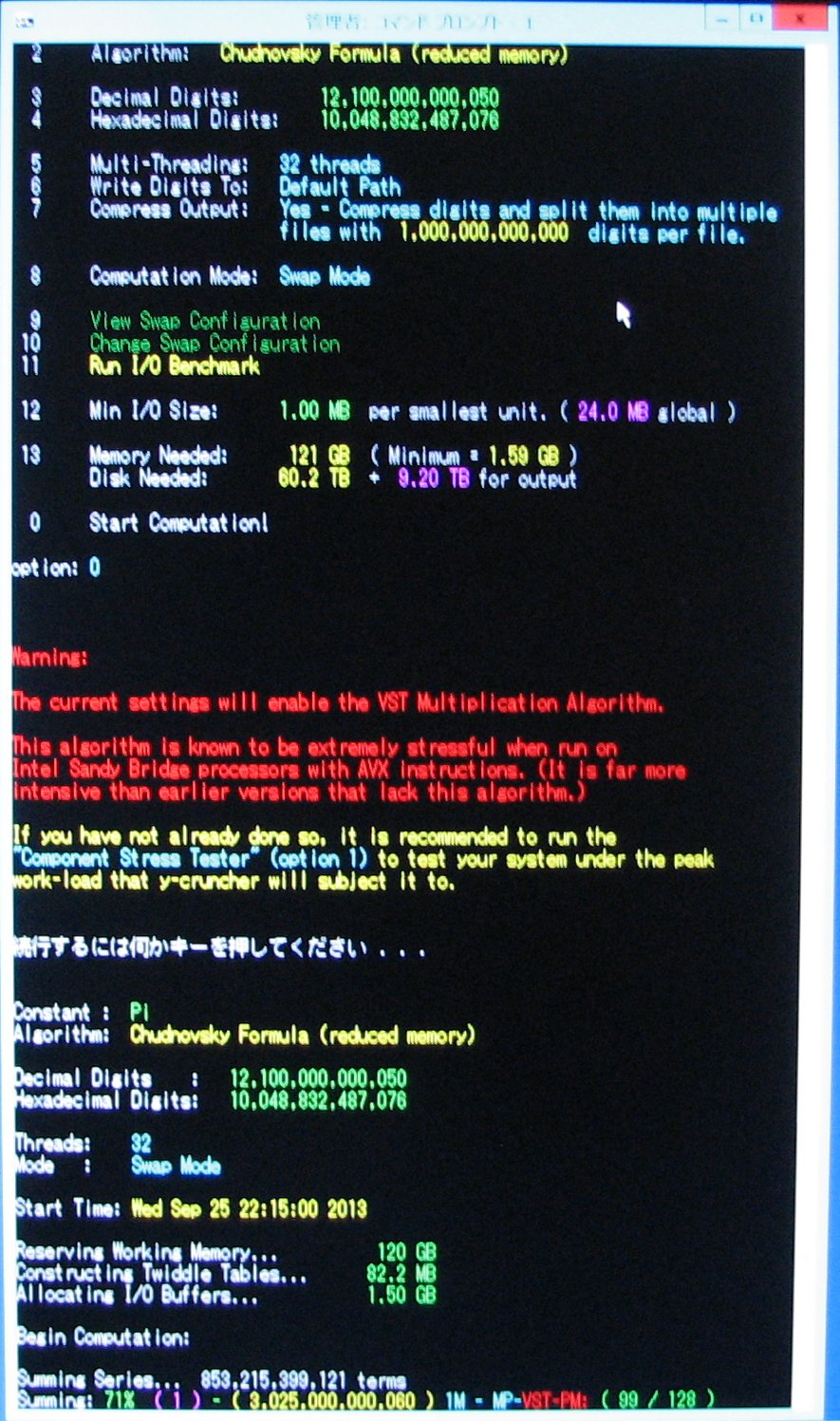
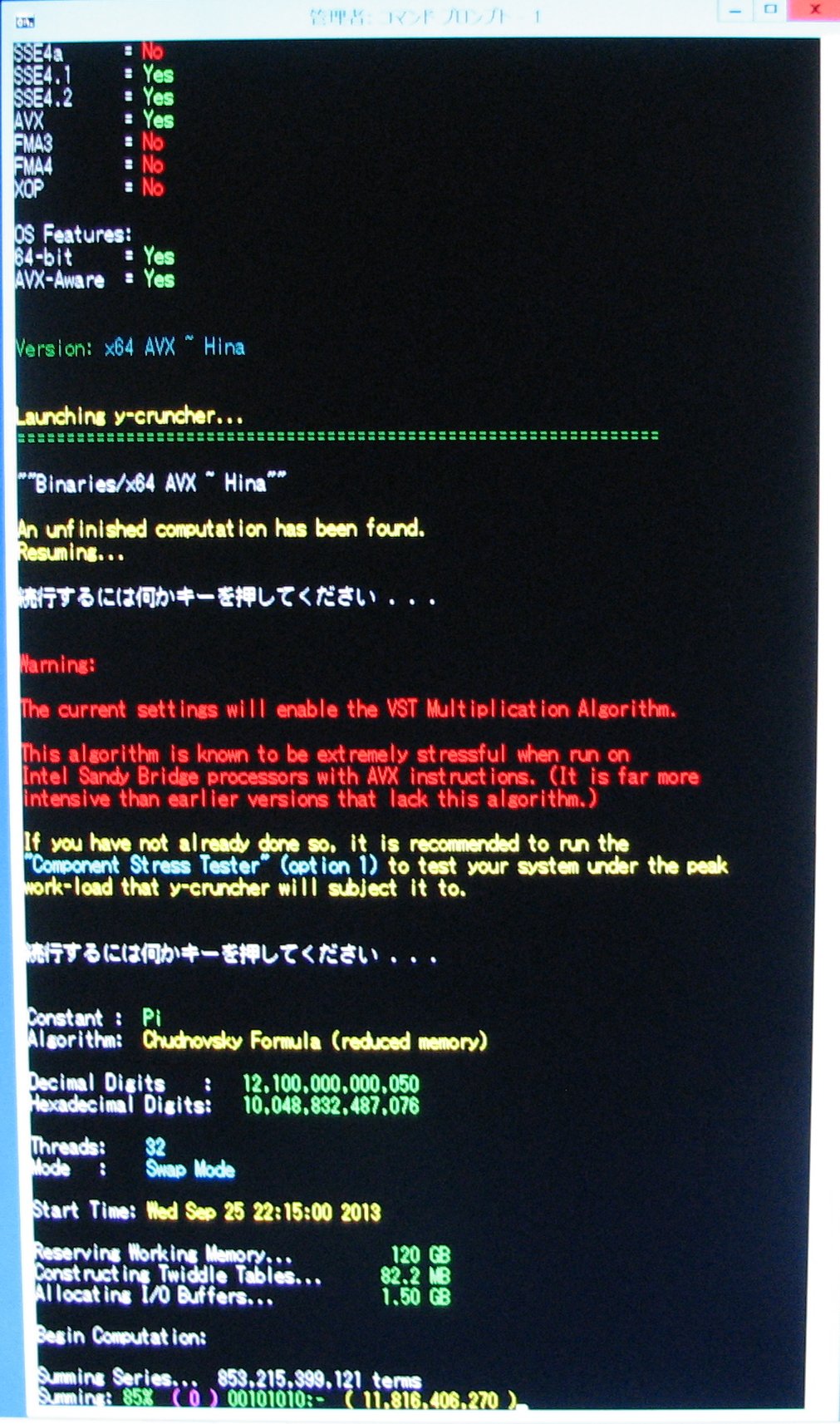
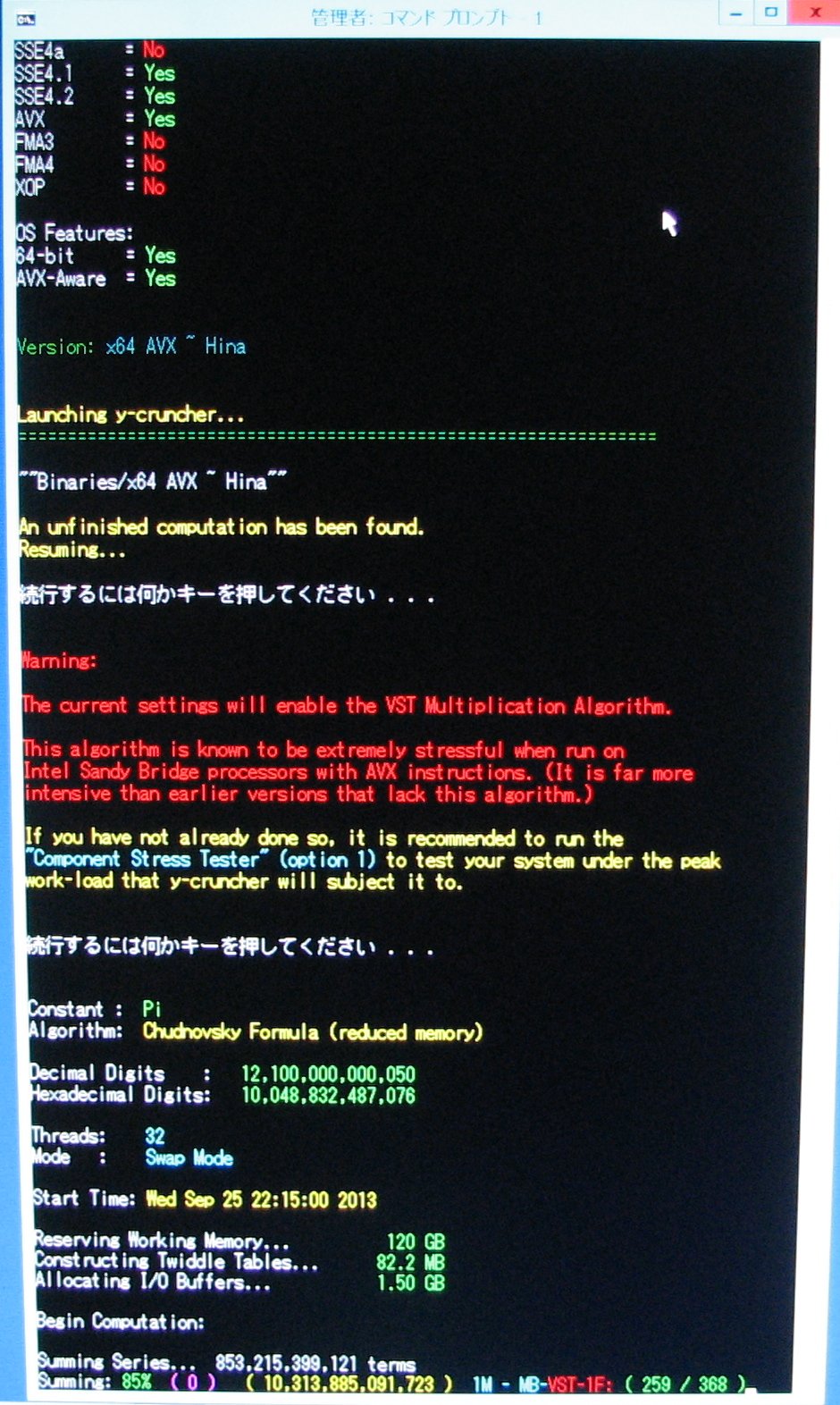
| November 23, 2013 | Series summation is 85% complete. |
|
| November 24, 2013 | Hard Drive Error: Read error followed by a spontaneous dismount of the hard drive. A bug is discovered in y-cruncher's checkpoint resuming function. So a patch had to be sent to Shigeru Kondo to properly resume the computation. |
View |
| November 27, 2013 | Week 9: Series summation is past 85% complete. |
View |
| December 3, 2013 | Hard Drive Error: Spontaneous dismount of a hard drive. (the same hard drive as before) |
|
| December 4, 2013 | Week 10: Series summation is still past 85% complete. |
View |
| December 5, 2013 | Hard Drive Error: Read error on the same hard drive. Spontaneous dismount of a different hard drive. Both hard drives are replaced and a backup of the computation is made before resuming. |
|
| December 9, 2013 | Series summation is complete. |
|
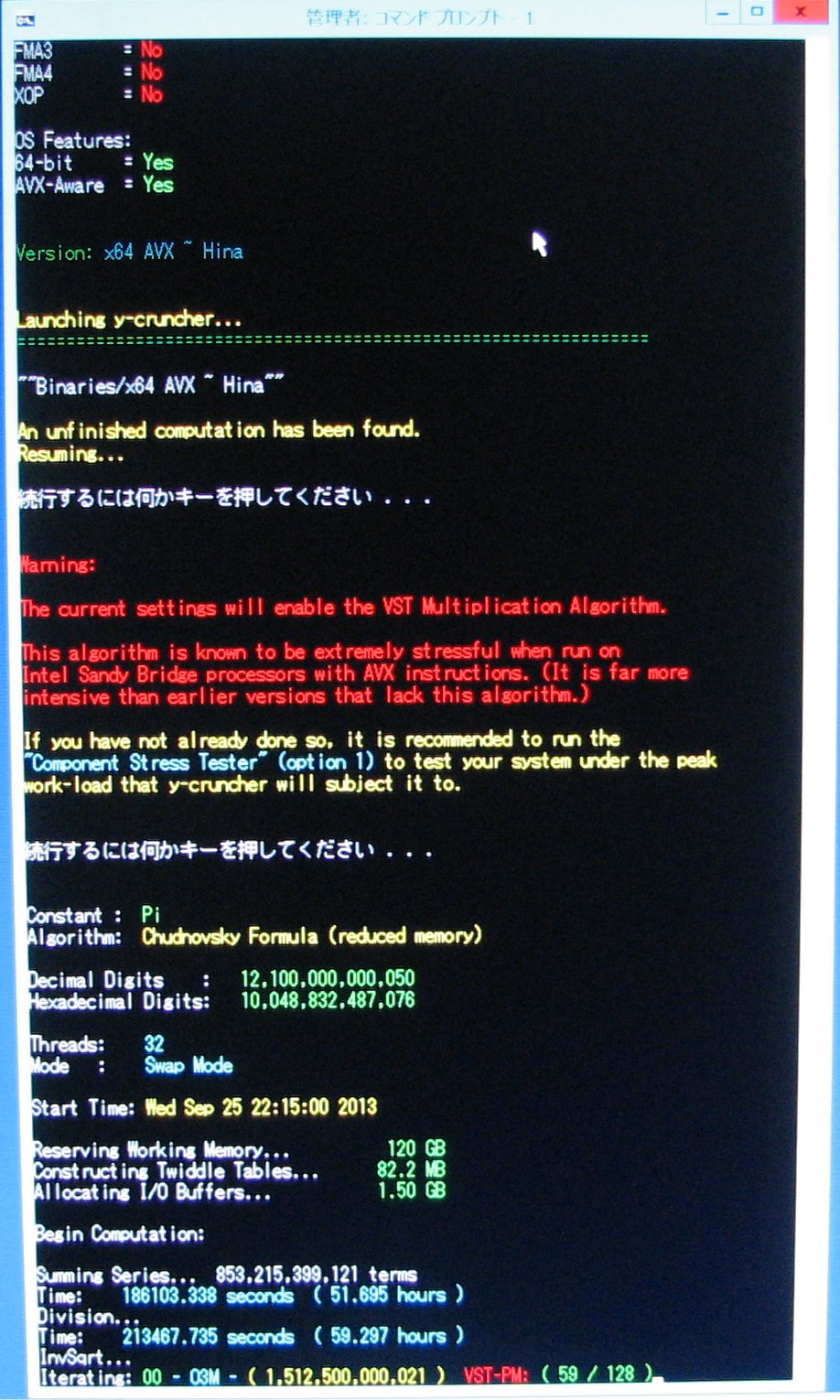
| December 10, 2013 | Division is complete. |
|
| December 11, 2013 | Week 10: Performing Square Root. |
View |
| December 14, 2013 | Day 80: Computation of binary digits is complete. Results match BBP formula. |
View |
| December 17, 2013 | Day 83: Base conversion is in progress. |
View |
| December 18, 2013 | Week 12: Still performing base conversion. |
View |
| December 20, 2013 | The conversion is complete and the digits are written to disk. The digits match the 10 trillion digit computation. |
|
Hard Drive Error: Read error. The hard drive is replaced. The computation is rolled back to the start of the base conversion. |
||
| December 25, 2013 | Week 12: Still performing base conversion. |
View |
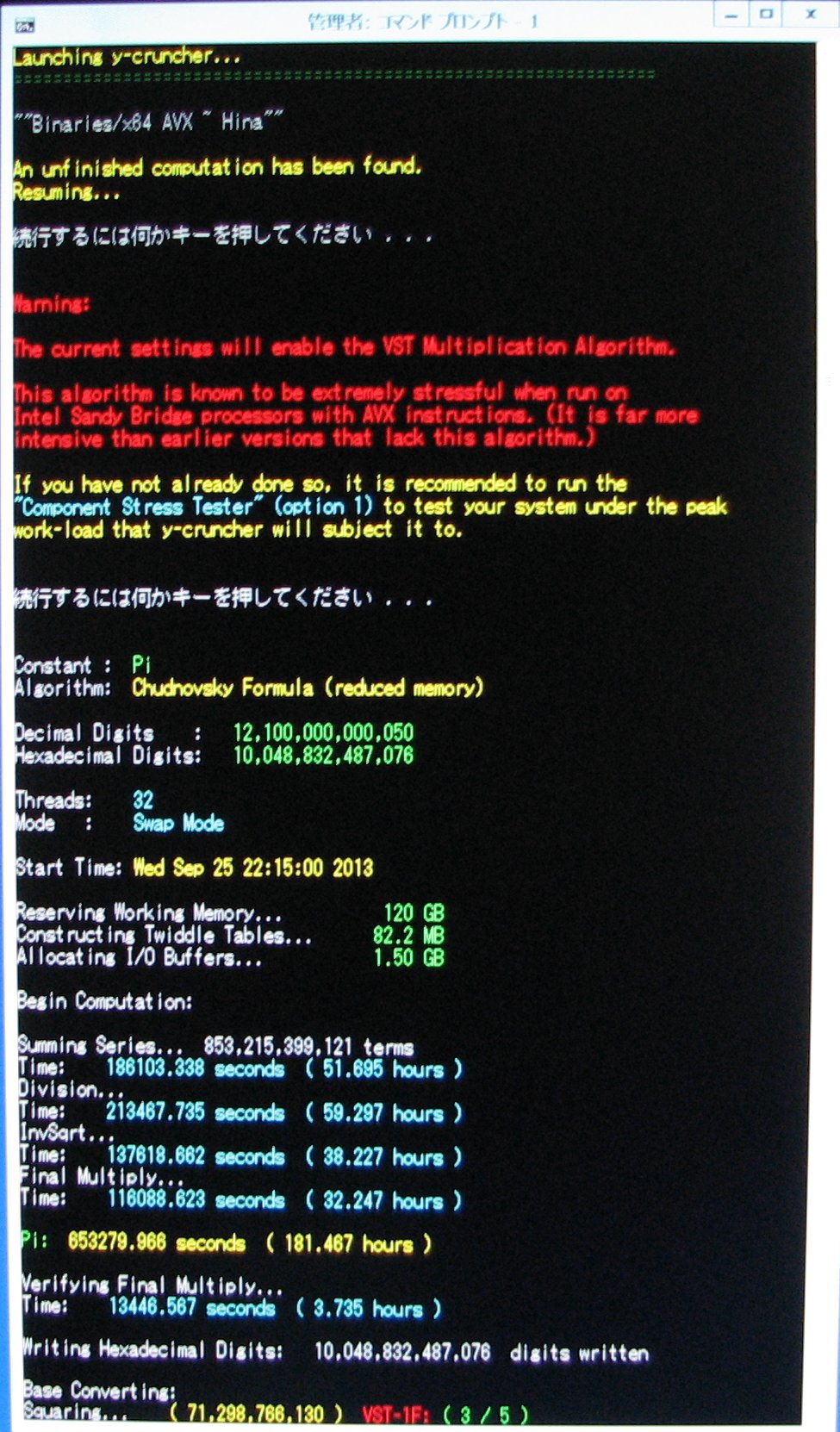
| December 28, 2013 | Day 94: Computation is Complete |
View |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
For those curious of the programming environment that was used to develop the y-cruncher software... (if can even be considered a "programming environment")
 |
 |
 |
It didn't always look exactly like this... The computers change regularly. And the monitors weren't as big when I was still in school.
But what did stay constant was the large variety of computers that were used to develop and tune the y-cruncher program (among other things). This variety is necessary for developing code that performs well on different hardware and is also a side-effect of building new machines and never tossing out the old ones.
As of this writing, there are 6 active machines - 3 of which are in the pictures above:
| Processor(s) | Generation | Memory | Primary Storage | Swap Configuration | ||
| Core i7 920 | 3.5 GHz (OC) | Intel Nehalem | 12 GB DDR3 | 1333 MHz | 2 TB | - |
| Core i7 3630QM | 2.4 GHz | Intel Ivy Bridge | 8 GB DDR3 | 1600 MHz | 1 TB | - |
| FX-8350 | 4.2 GHz (OC) | AMD Piledriver | 16 GB DDR3 | 1333 MHz | 2 TB | - |
| Core i7 4770K | 4.0 GHz (OC) | Intel Haswell | 32 GB DDR3 | 1866 MHz | 1.5 TB | 4 x 1 TB + 4 x 2 TB |
| 4 x Opteron 8356 | 2.31 GHz | AMD Barcelona | 8 GB DDR2 | 533 MHz | 80 GB + 1 TB | - |
| 2 x Xeon X5482 | 3.2 GHz | Intel Harpertown | 64 GB DDR2 | 800 MHz | 64 GB SSD + 2 TB | 8 x 2 TB |
While these aren't as powerful as the computer we used for the computation, most of them are at least mainstream enthusiast hardware. There used to be more of them, but most are retired. One was handed down to a relative. One was left behind with a friend in Illinois when I left school. And one was recently destroyed due to a careless short circuit (a Core i7 2600K @ 4.6 GHz).
Contact us by e-mail.
- Alexander Yee - [email protected]
- Shigeru Kondo - [email protected]
You can also find me on:
- The XtremeSystems Forums thread for y-cruncher. This is where I answer most overclocker questions about the program.
- And on Stack Overflow:
