Zen5's AVX512 Teardown + More...
By Alexander J. Yee (@Mysticial)
(Last updated: March 14, 2025)
Shortcuts:
This article was supposed to be published all at once on July 30'th. But because of the staggered launch delay into August 8 and 15, some sections of this article were redacted until August 14th.
So Zen5 is here! And with all the hype around its AVX512 capability, this will be the sequel to my Zen4 AVX512 teardown from 2 years ago.
Like last time with Zen4, AMD has graciously provided me a chip ahead of launch. But unlike last time, much of the architecture of Zen5 had already been revealed in AMD's GCC patch. So this time, the chip I was analyzing was not as much of a black box. Nevertheless, there are still numerous surprises that were not revealed by either the GCC patch or any of the leaks up to this point.
Once again, I would like to thank George, Chester, and Ian Cutress from Chips and Cheese for their help with some of the off-the-shelf tools for analysis. Not all the analysis I do is with my own tools and I do rely a lot other software/tools.

|

AVX512 has come a long way. Intel first launched it in the consumer space with Skylake X in 2017 and it took AMD another 5 years to finally copy it with Zen4 in 2022.
But AMD's first AVX512 implementation (in Zen4) was not a "native" implementation. Instead, it reused the existing 256-bit hardware from Zen3 by "double-pumping" 512-bit instructions into the 256-bit hardware on consecutive cycles. Nevertheless, it still provided a very competitive AVX512 implementation compared to Intel.
In my Zen4 AVX512 teardown article, I said this:
Implement 512-bit as 2 x 256-bit first.... Then in the future, when the silicon allows for it and the demand calls for it, widen things up to 512-bit.
... if in the future AMD decides to widen things up, you may get a 2x speedup for free.
Little did I know that not only was this going to happen, it was going to happen the very next generation! As much as I was amazed with how my silicon AMD had to throw around for various parts of their Zen4 implementation of AVX512, Zen5 brings this to a whole new level.
Zen5 improves upon Zen4 by doubling all the hardware for AVX512. Nearly all datapaths and execution units have been expanded to 512-bit wide. Thus Zen5 becomes the first desktop processor to be capable of 4 x 512-bit execution throughput.
To top it off, they did this without increasing the die size of the core complex. (Though I suspect this is more an indication of Zen4 being inefficient rather than Zen5 being amazing.)
With this, AMD has finally surpassed Intel in nearly every category related to SIMD execution - crushing them in 512-bit performance. This is a massive turn-around from the days of Bulldozer and Zen1. Intel has historically been the pioneer of SIMD. But now, AMD has taken the crown from them and beaten them at their own game.
Zen5 Strix Point is different from Zen5 Desktop/Server
While Zen5 is capable of 4 x 512-bit execution throughput, this only applies to desktop Zen5 (Granite Ridge) and presumably the server parts. The mobile parts such as the Strix Point APUs unfortunately have a stripped down AVX512 that retains Zen4's 4 x 256-bit throughput. Thus we see that this is where AMD has finally drawn the line at how much dark silicon they are willing to throw around.
|
| Thanks to Jordan Ranous for lending me this laptop! |
| Codename | Product Type | Architecture | SIMD Width | SIMD Execution Throughput |
| AMD Raphael | Desktop | Zen4 | 4 x 256-bit | 1024 bits / cycle |
| AMD Dragon Range | Exteme Mobile | Zen4 | 4 x 256-bit | 1024 bits / cycle |
| AMD Phoenix | Mobile | Zen4 | 4 x 256-bit | 1024 bits / cycle |
| AMD Genoa | Server | Zen4 | 4 x 256-bit | 1024 bits / cycle |
| AMD Bergamo | Server | Zen4c | 4 x 256-bit | 1024 bits / cycle |
| AMD Granite Ridge | Desktop | Zen5 | 4 x 512-bit | 2048 bits / cycle |
| AMD Fire Range | Exteme Mobile | Zen5 | 4 x 512-bit ? | 2048 bits / cycle ? |
| AMD Strix Point | Mobile | Zen5 + Zen5c | 4 x 256-bit | 1024 bits / cycle |
| AMD Strix Halo | High-end? Mobile | Zen5 ? | ? | ? |
| AMD Turin | Server | Zen5/Zen5c? | 4 x 512-bit ? | 2048 bits / cycle ? |
| Intel Skylake X | Desktop/Server | Skylake | 3 x 256-bit 2 x 512-bit |
768 bits / cycle 1024 bits / cycle |
| Intel Cannon Lake | Mobile | Palm Cove | 3 x 256-bit 2 x 512-bit |
768 bits / cycle 1024 bits / cycle |
| Intel Ice Lake | All | Sunny Cove | 3 x 256-bit 2 x 512-bit |
768 bits / cycle 1024 bits / cycle |
| Intel Tiger Lake | Mobile | Willow Cove | 3 x 256-bit 2 x 512-bit |
768 bits / cycle 1024 bits / cycle |
| Intel Alder/Raptor Lake | Mobile/Desktop | Golden Cove Gracemont |
3 x 256-bit 3 x 128-bit |
768 bits / cycle 384 bits / cycle |
| Intel Sapphire Rapids | Server | Golden Cove | 3 x 256-bit 2 x 512-bit |
768 bits / cycle 1024 bits / cycle |
| Intel Lunar/Arrow Lake | Mobile/Desktop | Lion Cove Skymont |
4 x 256-bit 4 x 128-bit |
1024 bits / cycle 512 bits / cycle |
To be clear, Zen5 mobile still supports the full AVX512 instruction set. But the performance will be similar to Zen4 where the throughput of 512-bit instructions are halved by means of running through 256-bit hardware twice. Nevertheless, this stripped-down AVX512 is still better than most of Intel's offerings.
In February when the GCC patch revealed that Zen5 would have native AVX512, it came as a surprise to many. Nobody thought AMD would make such a leap this quickly after Zen4 (if ever).
But then news of Strix Point stripping it back down to 256-bit came as much of a surprise since that immediately implies that AMD bifurcated their Zen5 architecture into at least 4 different cores:
- Zen5 with 512-bit datapath
- Zen5c with 512-bit datapath
- Zen5 with 256-bit datapath
- Zen5c with 256-bit datapath
So far, my limited testing reveals that Strix Point's nerfing of the AVX512 goes beyond just halving the 512-bit throughput. The FADD and possibly even the register file also appear to be cut down.
AVX512 is Impressive, Memory Bandwidth is not
 |
|
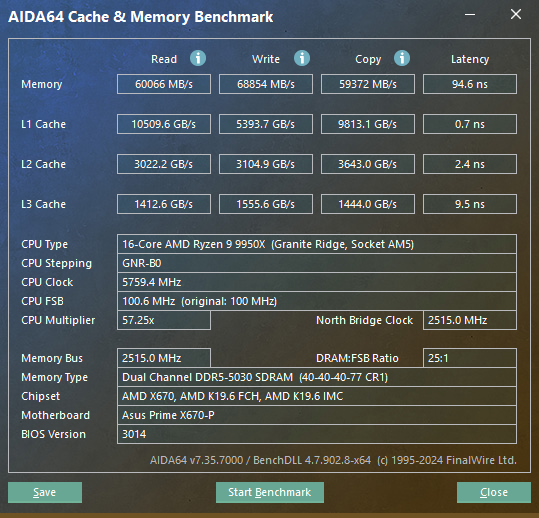
y-cruncher's core operation loses over 3x performance when it spills out of cache into memory. Hardware: Ryzen 9 9950X @ stock, DDR5 @ 4800 MT/s |
(This section was formerly redacted until August 14.)
As impressive as the full Zen5's AVX512 is, AMD has not done much to alleviate the biggest bottleneck that's holding it back - memory bandwidth.
AVX512 is most heavily used in HPC (high performance computing). Unfortunately, these workloads also tend to be the most memory-bound.
To the right is an AIDA64 benchmark of Zen5's memory bandwidth with memory at 5000 MT/s. You can argue that 5000 is underclocked and slower than AMD's official 5600 MT/s. But the reality is that an even lower setting of 4800 MT/s is default that most off-the-shelf and casual-built systems will be configured to.
AIDA64 measures Zen5's memory bandwidth to be about 60 GB/s. To the untrained eye, this may seem like a lot. But when you break it down, it becomes clear that it is suffocatingly insufficient for Zen5's computational power.
- 60 GB/s divided across 16 cores becomes 3.75 GB/s per core.
- 3.75 GB/s divided by ~5 GHz CPU clock becomes 0.75 bytes/cycle.
- 0.75 bytes/cycle divided by 512-bit load becomes 0.0117 loads/cycle.
- 1/0.117 loads/cycle = 85.3 cycles per load.
- Zen5's 4 x 512-bit execution width means 4 x 85.3 = ~340 instructions/load.
In plain English:
A loop that streams data from memory must do at least 340 AVX512 instructions for every 512-bit load from memory to not bottleneck on memory bandwidth.
Needless to say this is extremely difficult to achieve in real-world code. Given how powerful modern instructions are, rarely do workloads require 340 instructions per "unit of data" to do their thing. For example, computing the sum of an array is just 1 instruction per "unit of data".
This is where advanced optimization techniques like cache blocking come to play.
But even with complicated optimizations, there are limits. Suppose your workload needs to read+write all its memory exactly once and you've optimized it to the point where it is almost as fast as a memcpy() of the dataset. You've become "memory-optimal" and have reached the limit of what your memory bandwidth will allow. Nearly all linear-compute/linear-memory workloads such as FFT, base64 decoding, JSON parsing, AES encryption etc... have either reached this point or are getting close to it.
Taking y-cruncher as an example (which I'm the author of), the top 16-core SKUs for Zen2, Zen3, and Zen4 are all approximately 2-to-1 memory-bound. Meaning they need twice as much memory bandwidth to avoid significantly bottlenecking on memory access.
For the 16-core Zen5, the improved AVX512 throughput doubles the compute throughput while keeping the memory bandwidth unchanged. The result: 4-to-1 memory bound. (though the actual number is lower since AVX512 will throttle the clock speed)
This is like doubling the # of cars during rush-hour traffic without also doubling the # of lanes. You get congestion so bad that nothing ever moves. This is what Zen5 has become for workloads that need to touch memory.
For the 16-core 9950X to not be bottlenecked by memory here, it needs DDR5-20000. And y-cruncher is probably one of the better memory-optimized programs on this side of dense matrix. Common workloads like FFT, and BLAS levels 1 and 2 stand no chance.
This memory bottleneck is what keeps Intel competitive in the HPC space. You don't need to have a powerful CPU if it's all going to be held back by memory access anyway. Thus AMD's impressive AVX512 implementation really only shines in low-core-count SKUs or in embarassingly parallel workloads that don't touch memory.
So by the time you are reading this, the standard reviews for the 9950X are probably already out. And the pattern that you may be seeing on desktop is that the top SKUs for both Intel and AMD all perform roughly the same for y-cruncher's multi-threaded Pi computations. But at the lower-end, the lower-core count SKUs will likely have Zen5 crushing all other competition at the same price range - both Intel as well as AMD's older CPUs.
Why were Zen5 IPC leaks all over the place?
Leaks about Zen5's IPC improvement have been all over the place. And while AMD has officially stated that the average IPC improvement over Zen4 is 16%, the numbers being averaged behind it are as random as throwing darts after being spun around in circles blindfolded.
Numbers ranged from a low as 5% (mostly Zen 5% memes) to 40% SpecInt, to 2x AVX512. And while it may seem obvious to some, there is a simple reason behind it - there are many different types of workloads and Zen5 improves on them very unevenly. Some things improved a lot while other things gained virtually nothing.
How a benchmark performed depended on where it landed. And it didn't help that Zen5 desktop and Strix have different AVX512 implementations - thus contributing even more variation to benchmark performance.
If we look at pure homogenous CPU workloads with no memory bottleneck, here's what I get from just my own tests (largely taken from my own projects):
| Workload | IPC Improvement: Zen4 -> Zen5 (Granite Ridge) | Application |
| Scalar Integer | 20% 30 - 35% |
C++ Code Compilation Basecase large multiply. Scalar 64-bit NTT kernels. |
| x87 FPU | 10 - 13% | PiFast, y-cruncher BBP (00-x86) |
| 128-bit SSE | -1% (regression) | y-cruncher BBP (05-A64 and 08-NHM) |
| 256-bit AVX | 5 - 8% | y-cruncher BBP (19-ZN2) |
| 512-bit AVX512 | 96 - 98% (basically 2x) | y-cruncher BBP (22-ZN4) and various internal kernels |
So we can see that Zen5's biggest gains are in scalar integer and AVX512. Everything else is mediocre to disappointing. The improvement to x87 is an interesting surprise though. I don't know what the relevant architectural improvement is, but I doubt it is specific to x87 since nobody besides SuperPi benchmarkers care about x87 anymore. The slight performance regression in pure 128-bit SSE is surprising, but likely the result of some latency regressions which will be covered later.
The popular benchmarks Cinebench and CPU-Z showed disappointing gains of 10-15%. But that's because they both happen to hit Zen5's weakest categories:
- Cinebench is a mix of scalar SSE and 256-bit AVX.
- CPU-Z is almost exclusively scalar SSE.
A 10-15% IPC improvement in these categories is still larger than what I observed in my own tests. I will touch on this later.
The 40% IPC improvement in SpecInt (an early leak) is consistent with my tests showing 30-35% improvement in raw scalar integer that isn't memory-bound. (this leak has since been debunked as a fake)
The leaks of 2x improvement in AVX512 were spot on. This is huge, but comes as no surprise since AMD already revealed it in their GCC patch in February.
For y-cruncher:
- The regular Pi benchmarks and computations gain almost nothing (1-3%) on Zen5 due to being bottlenecked by memory bandwidth.
- If you run single-threaded, you remove the memory bottleneck and get a ~50% IPC improvement on Zen5 thanks to AVX512. (less than 2x due to Amdahl's Law)
- y-cruncher's BBP test (now a benchmark) shows 98% IPC improvement due to the pure AVX512 without any memory access.
In fact, the AVX512 improvement on Zen5 created a memory bottleneck so large that it became the primary reason why I promoted the BBP mini-program from a tool for verifying Pi records to a formal benchmark. The regular benchmarks wouldn't do Zen5 (and future processors) any justice. At least until someone can figure out how to get DDR5-20000 on AM5...
Is the clockspeed really still 5.7 GHz?
(This section was formerly redacted until August 14.)
One of the unexpected disappointments of Zen5 is that the max clock speed of the top two SKUs remain unchanged at 5.6 and 5.7 GHz respectively.
| Zen4 | Zen5 | |
| 6-core | 7600X - 5.3 GHz | 9600X - 5.4 GHz |
| 8-core | 7700X - 5.4 GHz | 9700X - 5.5 GHz |
| 12-core | 7900X - 5.6 GHz | 9900X - 5.6 GHz |
| 16-core | 7950X - 5.7 GHz | 9950X - 5.7 GHz |
This came as a big surprise to many people - especially me. My testing on early Zen5 hardware revealed that Zen5 required significantly lower voltages to reach the same clock speeds as Zen4. Thus I fully expected there to be enough headroom for AMD to push the official clock speeds higher.
 |
|
| Zen5 requires significantly less voltage than Zen4 to achieve the higher clock speeds. | |
It was only after AMD sent me a 9950X qualifying sample did it become clear what the deal was - which is best explained as a timeline:
September 2022: AMD launches Zen4. The 7950X clocked at 5.7 GHz which was easily achievable in many lightly threaded and low-intensity workloads.
However, this 5.7 GHz would crash the chip under certain AVX workloads. The work-around was to lower the clock speed to 5.5 GHz by applying a -200 MHz offset to the PBO (Precision Boost Overdrive).
January 2023: AMD releases the AGESA 1.0.0.4 microcode update. It effectively drops the clock speed from 5.7 GHz to 5.5 GHz to fix the AVX instability - thus formalizing the workaround. While 5.7 GHz was still possible, it required operating conditions that were unrealistic and unlikely to be sustainable in any real-world workloads.
August 2024: AMD launches Zen5. The 9950X is also clocked at 5.7 GHz. But unlike the 7950X, the 9950X's 5.7 GHz is both easily achievable in normal operating conditions and is fully stable with all workloads.
So what happened is that AMD launched Zen4 at clock speeds that were too high for the silicon to handle. So they nerfed it down by 200 MHz. But to avoid false advertising, the door to 5.7 GHz is kept open through a narrow road of unrealistic thermal conditions that would guarantee stability.
For Zen5, AMD did in fact increase the clock speeds - by at least 200 MHz. But rather than advertising it, they used it to reclaim the 200 MHz they lost in Zen4 and ensure that the 5.7 GHz is actually real this time. So it seems likely that the 9950X can be pushed higher than the 7950X via overclocking, though I have not tried.
So by increasing the engineering margins for Zen5, AMD is reducing the chance of an Intel-like debacle with their Raptor Lake CPUs.
(This section was formerly redacted until August 14.)
|
Source: AMD Tech Day 2024 |
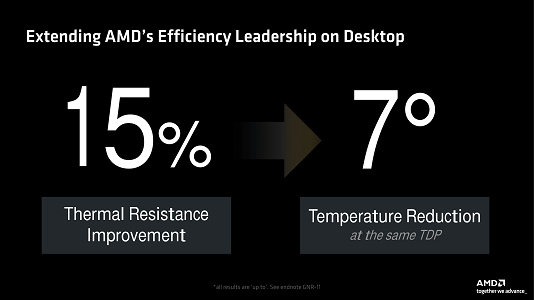
One of the biggest problems with Zen4 desktop is the heat dissipation. On the 16-core 7950X, nearly every all-core workload would overheat the CPU by shooting it to 95C. Slapping on high-end coolers like tower heatsinks or 360 AIOs wouldn't change that since it simply allowed the CPU to boost higher and get back to 95C.
To get an idea of how bad it was, Zen4 has trouble exceeding 250W draw on AM5 without overheating. By comparison, Intel's Raptor Lake can pull 450W no questions asked. (though they currently have bigger problems that are beyond the scope of this article)
In any case, the resulting throttling for Zen4 meant that performance became a function of how powerful the cooling was since no amount of cooling short of direct-die or subzero was sufficient. The problem largely stemmed from the dies being very small and having very little contact area with the IHS, which in turn is overly thick.
For Zen5, AMD claims to have improved the thermals. And while I agree with this claim in principle, my testing contradicts their claim on how they have improved it.
In my test setup with a 360 AIO:
- Zen4 7950X can draw up to 210W before it begins overheating at 95C.
- Zen5 9950X will hit 95C at around 200W.
So by this metric, Zen5 is actually slightly worse - though within the margin of error.
|
Left: Zen4 7950X, Right: Zen5 9950X |

However, both chips have a 160A current limit.
- The 7950X cannot easily hit 160A because it overheats before that can happen.
- The 9950X cannot easily overheat because it hits either the 160A current or the 200W power limit before that can happen.
As mentioned earlier, Zen5 requires less voltage to achieve the same clock speeds as Zen4. Less voltage means less heat/power per amp of current.
Therefore, Zen5 does indeed have better thermals than Zen4. However, this is not because it has better heat dissipation, but because it is more efficient and therefore produces less heat.
In other words, it feels like AMD has been underselling this.
Does Zen5 throttle under AVX512?
Yes it does. Intel couldn't get away from this, and neither can AMD. Laws of physics are the laws of physics.
The difference is how AMD does the throttling, as it's very different from Intel's approach and has virtually no negative side-effects.
(The rest of this section was formerly redacted until August 14.)
Intel's Approach:
Intel's approach is to throttle the moment it sees an AVX or AVX512 instruction*. The amount of throttling is usually determined by the "AVX offset" and "AVX512 offset" settings in the BIOS. Servers generally have more complicated throttling curves that depend on the # of active threads.
If a program running mostly "normal" code calls into a small library that uses AVX512, the clock will drop rather sharply - which hurts overall performance. Thus AVX512 was only useful if used in a high enough concentration to offset the frequency drop.
Think of Intel's AVX512 throttling in Skylake X to be like dropping a nuke on your own city because there is one enemy spy.
Therefore, they recommend that you replace the entire population with enemies to make your nuke "worth it".
Needless to say, this kind of collateral damage was not well received by the community - thus contributing to AVX512's troubled history.
But why did Intel throttle AVX and AVX512? Thermals and stability.
Fundamentally, you cannot run that much extra hardware without consuming a lot of power. So to keep the CPU from melting when running AVX512 on all cores, it will need to throttle down. This part is more or less unavoidable.
However, Intel's early AVX512 implementation on Skylake X also throttled for one more reason - stability. While running AVX512 on all cores at full speed will melt the chip, there should still be enough thermal budget to run a single thread of AVX512 at full speed. But this does not happen. The AVX and AVX512 offsets prevent this. And if you force the CPU to do it (by setting the offsets to zero), it will crash. (yes, I have tried...)
In short, Intel's early AVX512 CPUs were simply incapable of running AVX512 at full speed - at least not without excessive voltage (overclocking). It's unclear if modern Intel CPUs still have this problem. I do not have a modern Intel CPU that is both overclockable and has AVX512. (only overclockable systems allow overriding the AVX and AVX512 offsets)
(*Obviously oversimplifying here. The actual behavior is that the CPU needs to see "enough" AVX(512) instructions of the right type before it throttles. During the grace period from when the first AVX(512) instruction is seen to when the throttle happens, AVX512 instructions are much slower - likely "multi-pumped" through the lower lanes of the vector hardware.)
AMD's Approach:
Zen5's method of throttling appears to be mostly (if not entirely) thermal-based. Throttling generally only happens when some sort of thermal limit is exceeded (temperature, power, current). There is no artificial throttling simply because the CPU sees a couple AVX(512) instructions. AMD does not do AVX offsets.
Here are the benchmark and thermal results while running y-cruncher v0.8.5 BBP 100b. Both chips are running at stock settings. Both are using identical 360 AIOs.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
*Cells highlighted in pink have reached or exceeded the limit and thus resulted in throttling.
For context, the (stock) thermal limits are as follows:
| Tj.Max | Power Limit (PPT) | Current Limit (TDC) | |
| Ryzen 9 7950X (Zen4) | 95 C | 230 W | 160 A |
| Ryzen 9 9950X (Zen5) | 95 C | 200 W | 160 A |
Just to get a couple basic observations out of the way:
- The 7950X and 9950X top out at 5.55 GHz and 5.74 GHz respectively. This is the (unadvertised) 200 MHz gain that was mentioned in the earlier section. It is also lost very quickly as the workload intensifies. So top clock speeds are really more for marketing than actual functionality that end-users will notice.
- The performance of the benchmark (the "Time" column) scales super-linearly to the instruction set width. This is because of non-width related improvements to the instruction set. While this is irrelevant to the topic of thermal throttling, it does put into context the kind of performance gains that can be realized when you get this deep into the SIMD rabbit hole.
Now we get to the interesting stuff... Both the 7950X and the 9950X throttle very heavily on all-core workloads. Intensive AVX512 drops the 9950X by nearly 2 GHz! But for single-threaded AVX512, the throttling is much more mild. On Zen4 it's barely noticable while on Zen5 it's larger due to the full width execution.
It's unclear why both Zen4 and Zen5 still throttle single-threaded workloads when no thermal limits are being exceeded. But it's likely that there are per-core thermal limits. Unfortunately I can't confirm this since the usual hardware monitors cannot detect or read core-specific thermal information.
The BBP workload shown above is a rather extreme case in terms of workload intensity that sustains both 4 x 512-bit floating-point with heavy cache access. Take away either one and the core stays close to 5.7 GHz single-threaded. In other words, Zen5 can run AVX512 at full clock speed if the thermals allow it. By comparison, Intel's early AVX512 CPUs cannot do this.
Because AMD throttles on thermals, the throttling is much more fine-grained. Heavy AVX512 usage (4 x 512-bit/cycle) will have the largest amount of throttling. Lighter AVX512 usage (< 4 x 512-bit/cycle) will throttle less if at all. The effect is a smooth curve where the clock speed adjusts to the intensity of the workload to match some thermal limit.
Like Intel, AMD has nukes. But AMD also has precision weaponry that cause less collatoral damage. So they can snipe enemies in your city without killing too many of your own. But in the event that the entire city is taken over by the enemy, the nuke is there - armed and ready.
Thus on Zen4 and Zen5, there is no drawback to "sprinkling" small amounts of AVX512 into otherwise scalar code. They will not throttle the way that Intel does. The fact that Zen5 has full 512-bit hardware does not change this.
The throttling discussed in the previous section is for the steady state behavior. So if you sustain AVX512 on all cores for a long time, the CPU will eventually throttle down hard. (where "a long time" means a long time for the CPU - which can be just a few milliseconds in real time)
But what about the transients? What happens if the chip suddently goes from low-intensity code (like scalar integer) to high-intensity AVX512? This kind of thing happens quite often when "normal" code calls into an optimized library such as an MKL matrix multiply.
The problem with sudden code transitions like this is that they suddenly increase the power draw. And increased power draw causes vdroop, which can lead to instability. Normally, stability is maintained by having either the frequency or voltage regulation adapt to the new load. But these code transisions can happen in a matter of nanoseconds - far too quick for any external regulation to adapt to before bad things can happen.
Intel Processors:
For Intel processors, these transitions are handled in two phases:
- Upon transition from low-intensity code to higher-intensity, the high-intensity code runs at drastically reduced throughput to reduce its intensity.
- After a long period (~50,000 cycles), the higher intensity code will finally switch to full throughput.
As mentioned before, Intel processors cannot run AVX512 at full speed since they will crash. So before it can run AVX512, it first needs to lower the clock speed.
But lowering the clock speed requires interacting with the clock generator and voltage regulator, which takes time, ~50,000 cycles of it. It also requires powering on extra hardware which is only used by 512-bit instructions.
Rather than stalling the execution for the ~50,000 cycles needed to do this transition, Intel CPUs will break up the wider instructions and "multi-pump" them into the hardware that is already powered on and ready (and safe) to use at the current clock speed.
As a hypothetical example (since it's hard to know the actual behavior), at higher clocks, only the bottom 128 bits of the 512-bit hardware is powered on. At this speed, turning on the upper 384 bits will cause enough vdroop to crash the core. Only at lower speeds can the full 512 bits be powered on. But while you are waiting for the CPU to transition to the lower clock speed, you can still execute 512-bit instructions using that bottom 128 bits of hardware. It takes 4x longer, which is bad, but better than not doing anything at all.
This behavior was first observed by Agner Fog. So it begs the question of whether Zen5 also does this. In other words:
Does Zen5 temporarily revert to Zen4's double-pumping during a sudden transition to 512-bit code?
There are plenty of reasons to believe this. AMD already has an efficient double-pumping logic from Zen4 which they may be reusing for the mobile Zen5 parts.
AMD Processors:
The answer appears to be a "no" for both Zen4 and Zen5.
I wrote a set of benchmarks to test this behavior and managed to replicate Agner Fog's observations on both Skylake X and Tiger Lake. Then when I ran it on Zen4 and Zen5, I observed no transition period for all of the following scenarios:
- Scalar Integer -> 128-bit Floating-Point
- Scalar Integer -> 256-bit Floating-Point
- Scalar Integer -> 512-bit Floating-Point
- 128-bit Floating-Point -> 256-bit Floating-Point
- 128-bit Floating-Point -> 512-bit Floating-Point
- 256-bit Floating-Point -> 512-bit Floating-Point
By comparison, both Skylake X and Tiger Lake have transition periods for all of the above except scalar -> 128-bit. I have not tested other Intel processors.
So Zen5 can go from low-intensity integer code to 4 x 512-bit floating-point almost instantly*. There is no 50,000 cycle delay where 512-bit code runs at reduced throughput. Therefore, this behavior is consistent with the earlier observation that Zen5 can run AVX512 at full clock speed provided there is thermal headroom. Somehow Zen5 manages to keep all that extra hardware on standby and can wake it up instantly.
From the developer standpoint, what this means is that there quite literally is no penalty for using AVX512 on Zen5. So every precaution and recommendation against AVX512 that has been built up over the years on Intel should be completely reversed on Zen5 (as well as Zen4). Do not hold back on AVX512. Go ahead and use that 512-bit memcpy() in otherwise scalar code. Welcome to AMD's world.
How is AMD able to accomplish this? Do they have capacitors next to all the 512-bit hardware ready to unload at a moment's notice to buy time for the voltage and frequency regulation to adapt? Being a software guy, I have no idea. Though my circuit designer friends say that proper sizing of the power rails can effectively act as the "large capacitor" that is needed to take on a sudden power surge.
*I say "almost" instantly because there is a semi-consistent delay of around ~50 cycles for the most extreme transition (scalar integer to 4 x 512-bit) which does not happen as consistently with the other transitions. But it is difficult to tell if this stall is real or just an artifact of the test. The serializing effect of the RDTSCP instruction for clock measurement implies a heisenberg uncertainty of also around 50 cycles. If this delay is real, we can speculate if this is caused by clock-stretching or something else. Either way, it doesn't sound easy to test.
Key Differences from Zen4:
- Throughput of nearly all 512-bit instructions has been doubled up. (full Zen5 cores only)
- Latency of all 1-cycle SIMD instructions (regardless of width) has regressed to 2 cycles.
- 128-bit and 256-bit instructions remain largely the same - no improvement.
- SIMD register file (and thus reorder window) has increased from 192 to 384 with an additional 96 entry NSQ.
General Integer:
- # of ALUs increased from 4 to 6.
- 6 x ALU / cycle is not possible. Easy to hit 5/cycle, hard to get more. Most I can get in a synthetic is 5.5/cycle. Reason unknown - front end bottleneck?
- Multiply (lower half) improves from 1 -> 3/cycle.
- Multiply (upper half) remains 1/cycle.
- Shift improves from 2 -> 3/cycle.
- CMOV improves from 2 -> 4/cycle.
- CRC improves from 1 -> 3/cycle.
- PEXT/PDEP improves from 1 -> 3/cycle.
Integer Load/Store:
- 4 x load / cycle (up from 3 in Zen4)
- 2 x store / cycle
- Maximum 4 load/store per cycle of any type. Though it's difficult to get more than 3.5/cycle when a store is involved unless the loads are mirrored/forwarded.
General SIMD (512-bit Datapath):
- 4 x 512-bit / cycle is possible and very easy to achieve. (no real bottlenecks in the way)
- 4 x 512-bit / cycle IADD/bitwise. (except ternlog due to 10-port limit)
- 2 x 512-bit / cycle shift.
- 2 x 512-bit / cycle FADD.
- 2 x 512-bit / cycle FMUL/FMA/IMUL/IFMA.
- 2 x 512-bit FADD + 2 x 512-bit FMA / cycle (4 IPC) is possible.
- 4 x 512-bit / cycle simple shuffle (unpacks, VPSHUFD).
- 2 x 512-bit / cycle complex shuffle (anything crossing a 128-bit boundary including permutes such as VPERMT2B).
- FADD latency drops from 3 -> 2 cycles, but only if it can be forwarded. Otherwise remains 3 cycles.
- All formerly 1-cycle latency SIMD instructions now have 2-cycle latency. Applies to all widths - including scalar.
- All the throughputs shown above for 512-bit also apply to smaller vector lengths.
- All mask instructions are 2/cycle regardless of width. (Zen4 was 1/cycle for 64-bit mask)
- 10-port limit remains, though Zen5 is better at avoiding it either by forwarding or caching of operands.
SIMD Load/Store (512-bit Datapath):
- 2 x 512-bit load / cycle
- 1 x 512-bit store / cycle
- 1 x 512-bit load + 1 x 512-bit store / cycle is possible. (64 byte/cycle copy)
- 2 x 512-bit load + 1 x 512-bit store / cycle (3 IPC) is not possible. My tests show 2.5 IPC is the limit even when aligned. Reason unknown.
- 2 x 128/256-bit load / cycle
- 2 x 128/256-bit store / cycle
- 2 x 128/256-bit load + 2 x 128/256-bit store / cycle (4 IPC) does not look possible. Tests maxed out at only 2.76 IPC.
- 2 x mask load / cycle (all widths)
- 2 x mask store / cycle (all widths)
Specialized Instructions (512-bit Datapath):
- 0.5 x VPCLMULQDQ / cycle (all widths) - no change from Zen4
- 2 x AES / cycle (all widths)
- 2 x GFNI / cycle (all widths)
- 1 x V(P)EXPAND / cycle (all widths)
- 1 x V(P)COMPRESS / cycle (all widths)
- 1 x VPCONFLICT / cycle (256-bit and 512-bit)
- 2 x VPCONFLICT / cycle (128-bit)
- 1 x VP2INTERSECT / cycle (all widths)
Combinations:
- 4 x 512-bit EU + 1 x 512-bit store / cycle (5 IPC) is possible - but only if 10-port limit is not exceeded.
- 4 x 512-bit EU + 2 x 512-bit load / cycle (6 IPC) is possible. So 6 register writes/cycle is possible.
- 8+ IPC combined between integer and SIMD is possible. (Possibly even higher if you include 0-uop instructions, but have not tried to push it.)
Hazards Fixed:
- V(P)COMPRESS store to memory is fixed. (3 cycles/store to non-overlapping addresses)
- The super-alignment hazard is fixed.
Strix Point vs Granite Ridge Differences:
Strix Point (256-bit datapath) differs from Granite Ridge (512-bit datapath) in the following ways:
- All instructions that touch a ZMM register has half the throughput except for 512-bit store and VPCLMULQDQ.
- FADD latency is always 3 cycles. There is no 2 cycle forwarded path.
- The physical vector register file is only 256-bit wide. ZMM registers occupy 2 entries.
- The physical vector register file appears to be slightly smaller on Strix Point than Granite Ridge.
AIDA64 Instruction Latency/Throughput Dump:
- Zen5 Desktop (Granite Ridge): instlatdump-9950X.txt
- Zen5 Laptop (Strix Point):
- P-core: instlatdump-HX370-Pcore.txt
- E-core: instlatdump-HX370-Ecore.txt
Note that AIDA64 does not accurately measure some instructions. Known Errors:
| Instruction | AIDA64's Measurement | Correct Value | Notes |
| Most integer ALU instructions: ADD, SUB, AND, OR, XOR, ... |
T: 0.25c | T: 0.17c - 0.20c | Manually measured to 0.18c - better than AIDA64. Lower bound (6 ALUs) is 0.17c. |
| MULX r64, r64, r64 | T: 1.75c | T: 1.00c | Manually measured to 1/cycle - better than AIDA64. |
| Many "aligned LS pair" | Most of the values don't make any sense or are contradictory. Further investigation needed. |
||
KANDNB k, k, k KANDNW k, k, k KANDND k, k, k KANDNQ k, k, k KXORB k, k, k KXORW k, k, k KXORD k, k, k KXORQ k, k, k |
0.02c | 0.50c (not confirmed) |
AIDA64 reported value is impossibly low. Test may be using the same register which is move-eliminated. |
This section will assume the full Zen5 core with 512-bit datapaths.
512-bit is required for significant performance gain.
Zen5's improvement to the AVX512 is that it doubles up the the width of (nearly) everything that was 256-bit to 512-bit. All the datapaths, execution units, etc... they are now natively 512-bit. There is no more "double-pumping" from Zen4 - at least on the desktop and server cores with the full AVX512 capability.
Consequently, the only way to utilize all this new hardware is to use 512-bit instructions. None of the 512-bit hardware can be split to service 256-bit instructions at twice the throughput. The upper-half of all the 512-bit hardware is "use it or lose it". The only way to use them is to use 512-bit instructions.
As a result, Zen5 brings little performance gain for scalar, 128-bit, and 256-bit SIMD code. It's 512-bit or bust.
So sorry to disappoint the RPCS3 community here. As much as they love AVX512, they primarily only use 128-bit AVX512 - which does not significantly benefit from Zen5's improvements to the vector unit.
All SIMD instructions have minimum 2 cycle latency:
As awesome as Zen5's AVX512 is, not everything is perfect. So let's start with the biggest regression I found:
- All formerly 1 cycle SIMD instructions have regressed to 2 cycles.
- Applies to all widths, even 128-bit.
- Everything that was already >= 2 does not further regress.
- Throughput remains unchanged. The regression is only for latency.
- Instructions that can be rename-eliminated (i.e. XOR zeroing) are unaffected and remain zero latency.
This caught me by surprise since it wasn't revealed in AMD's GCC patch. Initially I suspected that this regression was a trade-off to achieve the full 256 -> 512-bit widening. So I asked AMD about this and they gave a completely different explanation. While I won't disclose their response (which I assume remains under NDA), I'll describe it as a CPU hazard that "almost always" turns 1-cycle SIMD instructions into 2-cycle latency.
So while the 1-cycle instructions technically remain 1-cycle, for all practical purposes they are now 2 cycles. So developers and optimizing compilers should assume 2 cycles instead of 1 cycle. I believe it is possible to construct a benchmark that demonstrates the 1-cycle latency, but I have not attempted to do this.
If the problem really is just a hazard, we can hope that it will be fixed in a future AMD processor. But for now, developers should just assume 2-cycle latency. Combined with the 4 x 512-bit capability, you now need a minimum of 8-way ILP to saturate Zen5 even for formerly 1-cycle instructions. This is a drastic increase from the 2-way ILP that was sufficient to satisfy all prior AVX512 implementations on both Intel and AMD.
Some of y-cruncher's carry propagation kernels got wrecked by this 2 -> 8 increase in required ILP due their inherent dependency chain. Mitigating this is one of the many micro-optimizations in the new Zen5-optimized binary for y-cruncher v0.8.5.
The full Zen5 core doubles up the 512-bit load/throughput from Zen4, but it doesn't do it symmetrically.
Zen4's load/store architecture is:
- 3 integer load ports. (3 integer loads/cycle)
- 2 integer store ports. (2 integer stores/cycle)
- 2 x 256-bit vector load ports. (2 x 256-bit load/cycle, or 1 x 512-bit load/cycle)
- 2 x 256-bit vector store ports. But only one can be used at a time. (1 x 256-bit store/cycle, or 0.5 x 512-bit store/cycle)
- Maximum 3 of any type of load/store each cycle.
- The store queue is 64 entries deep. 512-bit stores take 2 entries due to being split into 2 x 256-bit.
Zen5 improves on Zen4 by:
- Add one additional integer load port for a total of 4.
- The 2 x 256-bit vector load ports have been widened to 2 x 512-bit.
- Both store ports can now be used together for 2 x 256-bit store/cycle.
- At least one of the 2 store ports has been widened to 512-bit. But downstream appears limited to 2 x 256-bit. Thus 1 x 512-bit or 2 x 256-bit is the limit.
- The store queue is measured to ~108 entries deep. 512-bit stores still take 2 entries.
The result is: (where "Intel" refers to Golden Cove/Alder Lake P/Sapphire Rapids)
- 4 x scalar load / cycle. (better than Intel at 3/cycle)
- 2 x scalar store / cycle. (same as Intel)
- 2 x 256-bit load / cycle. (behind Intel at 3/cycle)
- 2 x 256-bit store / cycle. (better than Intel at 1/cycle)
- 2 x 512-bit load / cycle. (same as Intel)
- 1 x 512-bit store / cycle. (same as Intel)
- 2 x 256-bit load + 2 x 256-bit store each cycle (4 IPC) is not possible. Measured to 2.76 IPC. (still better than Intel)
- 2 x 512-bit load + 1 x 512-bit store each cycle (3 IPC) is not possible. Measured to 2.50 IPC. (still better than Intel)
The doubling of 1 x 256-bit store to 2 x 256-bit store is one of the few places where Zen5 improved on Zen4 for less than 512-bit wide SIMD.
Gather/Scatter has improved slightly from Zen4, but still remains behind Intel.
Overall, AMD has finally matched Intel in load/store performance after lagging behind it for many years. Of all the load/store categories, Intel remains ahead in only one of them: 128/256-bit load throughput where it can do 3/cycle while Zen5 is 2/cycle. For everything else that I have tested, Zen5 either matches or beats Intel's Golden Cove architecture.
But it's worth noting that Intel's Arrow Lake is expected to retake the lead in the integer/scalar department with 3 x load + 3 x store / cycle. We'll have to wait and see if this actually holds true.
512-bit stores are weird. When I first tested the stores, everything was pointing at Zen5 having 2 x 256-bit stores with 512-bit stores being split in two.
In a recent interview of Mike Clark (architect of AMD Zen), he mistakenly claimed that Zen5's store capability to be 2 x 512-bit. While that was resolved later, it nevertheless prompted me to test it a bit further in depth than usual. And it turns out that the situation is a bit more complicated than one would expect.
This sequence runs at 2 stores/cycle. Nothing unusual here. This is what everyone expected.
vmovaps YMMWORD PTR [...], ymm0
vmovaps YMMWORD PTR [...], ymm1
vmovaps YMMWORD PTR [...], ymm2
vmovaps YMMWORD PTR [...], ymm3
This sequence runs at 1 store/cycle. Again, nothing unusual here.
vmovaps ZMMWORD PTR [...], zmm0
vmovaps ZMMWORD PTR [...], zmm1
vmovaps ZMMWORD PTR [...], zmm2
vmovaps ZMMWORD PTR [...], zmm3
|
|
Zen5's Vector Architecture |
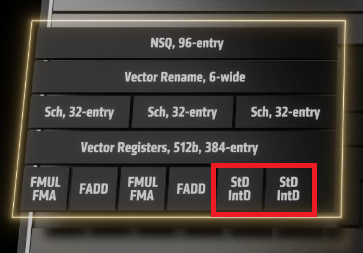
Direct measurements of the store-queue show that 512-bit stores take two entries in the store-queue. Therefore the most logical explanation is that the two store ports are 256-bits each - with 512-bit stores being split across them.
However... if we add instructions which share the same ports as the stores, we'll find that it doesn't slow down the stores.
This sequence still runs at 1 store/cycle.
vmovaps ZMMWORD PTR [...], zmm0
vmovaps ZMMWORD PTR [...], zmm1
vmovaps ZMMWORD PTR [...], zmm2
vmovaps ZMMWORD PTR [...], zmm3vmovd r10, xmm4
vmovd r11, xmm5
vmovd r12, xmm6
vmovd r13, xmm7
What? The only way this is possible is if 512-bit stores do not use both store ports simultaneously. That immediately implies that at least one of them (possibly both) are 512-bit, otherwise it wouldn't be possible to simultaneously execute both a 512-bit store and a VMOVD vector-to-integer instruction. Unfortunately, it does not seem possible to experimentally determine if the store ports are both 512-bit vs. 256 + 512-bit.
On Strix Point, both store ports are only 256-bit wide and both must be utilized to sustain 1 x 512-bit store/cycle. So the presence of VMOVD instructions will degrade vector store performance for all widths including 512-bit.
Design Speculation: Given that Zen5 is a major redesign and the first of multiple architectures using the design, it is possible that AMD designed the new vector unit to support 2 x 512-bit store. But since Zen5's store-queue and retirement are still limited to 2 x 256-bit, the full 2 x 512-bit will not be realized until a future Zen processor that widens those to 2 x 512-bit. In other words, AMD may be incrementally redesigning and improving different parts of the chip in a staggered fashion.
But there's more! Something interesting happens when you try mixing store sizes...
This sequence runs with 3 cycle throughput. There is a total of 6 x 256-bit here, thus 3 cycles. Nothing unusual here.
vmovaps ZMMWORD PTR [...], zmm0
vmovaps ZMMWORD PTR [...], zmm1
vmovaps YMMWORD PTR [...], ymm2
vmovaps YMMWORD PTR [...], ymm3
But if we change the order to interleave the 512-bit and 256-bit stores, the throughput drops to 4 cycles.
vmovaps ZMMWORD PTR [...], zmm0
vmovaps YMMWORD PTR [...], ymm2
vmovaps ZMMWORD PTR [...], zmm1
vmovaps YMMWORD PTR [...], ymm3
What happened here? There can be many possible causes - most of which are probably difficult or impossible to distinguish with microbenchmarks. But just to present one possibility:
- Zen5 somehow requires that 512-bit stores be retired on the same cycle for atomicity (possibly using the same path intended for the MOVDIR64B instruction). This means that alternating 512-bit and 256-bit stores will cause bubbles since a single 256-bit store will block a 512-bit store until the next cycle.
- Stores must retire in order to preserve total store ordering (TSO) as required by x86. Therefore they cannot be reordered to fill the bubbles.
Obviously this is pure speculation and would warrant further investigation. But regardless of the exact cause, the implication is that assembly writers and compiler developers should never split a pair of 512-bit stores with an odd number of smaller stores if the code is likely to be store-bound. This is the same for both Granite Ridge and Strix Point.
Looking back, Zen4 does not have this bubble, nor can it retire 512-bit stores in a single cycle. But Zen4 does not support MOVDIR64B and therefore does not need a way to implement atomic 512-bit store.
512-bit Byte-Granular Shuffle:
Zen5 has two of the 512-bit byte-granular shuffles. It can do the most expensive 512-bit byte-granular shuffles at 2/cycle. This is 4x that of Intel's best CPU.
AVX512VL_VBMI : VPERMI2B xmm, xmm, xmm L: 0.69ns= 3.0c T: 0.11ns= 0.49c
AVX512VL_VBMI : VPERMI2B ymm, ymm, ymm L: 0.93ns= 4.0c T: 0.11ns= 0.49c
AVX512_VBMI : VPERMI2B zmm, zmm, zmm L: 1.14ns= 4.9c T: 0.11ns= 0.50cAVX512VL_VBMI : VPERMT2B xmm, xmm, xmm L: 0.69ns= 3.0c T: 0.11ns= 0.49c
AVX512VL_VBMI : VPERMT2B ymm, ymm, ymm L: 0.93ns= 4.0c T: 0.11ns= 0.49c
AVX512_VBMI : VPERMT2B zmm, zmm, zmm L: 1.14ns= 4.9c T: 0.11ns= 0.50c
This was something that I inferred from the GCC patch which was hard to believe. But sure enough, it turned out to be true once I tested the actual hardware.
In my Zen4 teardown blog, I expressed amazement over the quality of its 512-bit shuffle due to its O(N2) silicon cost*. Well for Zen5, AMD has duplicated it. So now there are two of these massive execution units in the full Zen5 core.
Meanwhile, there are (credable) rumors suggesting that the 512-bit shuffle is one of the reasons why Intel chose to drop AVX512 from their E-cores.
- The 512-bit shuffle cannot be multi-pumped due to the inherent cross-lane dependencies.
- A native 512-bit shuffle is too expensive in silicon area.
- Microcoding the 512-bit shuffle would give very poor performance.
Regardless of what's going on behind Intel's doors, we are left with a world where AMD has a very powerful shuffle while Intel has none - at least in the consumer space.
Performance-wise, the dual 512-bit shuffles doubles up the throughput of 512-bit shuffles. But it doesn't help the narrower shuffles. (Sorry RPC3 folks!)
- On Zen4, the upper and lower halves of the 512-bit shuffle could be accessed separately to allow 128-bit and 256-bit shuffles to run at 2/cycle.
- On the full Zen5, the 512-bit shuffle can no longer be split - but there are two of them. Thus the 128-bit and 256-bit complex shuffles remain at 2/cycle.
- It's unclear what the Strix Zen5 does. But I suspect it's similar, if not the same as Zen4.
As I have mentioned already, Zen5's SIMD improvements almost universally require 512-bit to see any benefit - thus another example of "use it or lose it".
So despite the 512-bit shuffle taking a different path to doubling up the 512-bit performance, the result is the same. Only 512-bit gets the improvement. The performance of 128-bit and 256-bit complex shuffles remain unchanged from Zen4.
*A subsequent discussion showed that the 512-bit shuffle can be implemented in O(log(N)) transistors. However, the routing traffic/area likely remains O(N^2).
AMD has revealed that the FADD latency drops from 3 -> 2. But in my testing, this is only partially true. The 2 cycle latency is only possible if the data can be forwarded from a previous FADD. Otherwise, it remains 3 cycle latency.
To further complicate things, the 2-cycle latency only seems possible on Granite Ridge as I never observed it on Strix Point.
Forwarding Possible: 2 cycle latency FADD (Granite Ridge only)
vaddpd zmm0, zmm0, zmm0
vaddpd zmm0, zmm0, zmm0
vaddpd zmm0, zmm0, zmm0
vaddpd zmm0, zmm0, zmm0
Forwarding Not Possible: 3 cycle latency FADD
vfmadd213pd zmm0, zmm0, zmm0
vaddpd zmm0, zmm0, zmm0
vfmadd213pd zmm0, zmm0, zmm0
vaddpd zmm0, zmm0, zmm0
So Zen5's FADD behaves similar to Intel's 2-cycle FADD on Golden Cove. So while it's technically a 2-cycle instruction, in practice it will be closer to 3 cycles in real-world code that has both FADDs and FMUL/FMA.
However, while I compare Zen5's FADD to that of Golden Cove, actual performance of 512-bit FADD on Golden Cove is worse than 2-3 cycles. Even though the dedicated FADD hardware on Golden Cove is indeed 2-3 cycles (2 forwarded, 3 otherwise), in practice, the scheduler fails miserably to achieve this since many of the FADD ops get sent to the 4-cycle FMA hardware instead. So on average, 512-bit FADDs have 3.3 cycle latency on Golden Cove.
It is unclear why Intel's scheduler is so bad. So thanks to this unforced error by Intel, Zen5 takes the win here. (Zen4 also wins against Intel here.)
It is also unclear why Strix Point's FADD is still 3-cycles instead of the 2-cycles on Granite Ridge. Perhaps the 2-cycle FADD is significantly more expensive in area and power than a 3-cycle FADD and thus it was intentionally nerfed for Strix Point.
Ah yes, the black sheep of the AVX512 family...
There is a lot of history here, but to summarize:
- Intel added AVX512-VP2INTERSECT to Tiger Lake. But it was really slow. (microcoded ~25 cycles/46 uops)
- It was so slow that someone found a better way to implement its functionality without using the instruction itself.
- Intel deprecates the instruction and removes it from all processors after Tiger Lake. (ignoring the fact that early Alder Lake unofficially also had it)
- AMD adds it to Zen5.
So just as Intel kills off VP2INTERSECT, AMD shows up with it. Needless to say, Zen5 had probably already taped out by the time Intel deprecated the instruction. So VP2INTERSECT made it into Zen5's design and wasn't going to be removed.
But how good is AMD's implementation? Let's look at AIDA64's dumps for Granite Ridge:
AVX512VL_VP2INTERSE :VP2INTERSECTD k1+1, xmm, xmm L: [diff. reg. set] T: 0.23ns= 1.00c
AVX512VL_VP2INTERSE :VP2INTERSECTD k1+1, ymm, ymm L: [diff. reg. set] T: 0.23ns= 1.00c
AVX512_VP2INTERSECT :VP2INTERSECTD k1+1, zmm, zmm L: [diff. reg. set] T: 0.23ns= 1.00c
AVX512VL_VP2INTERSE :VP2INTERSECTQ k1+1, xmm, xmm L: [diff. reg. set] T: 0.23ns= 1.00c
AVX512VL_VP2INTERSE :VP2INTERSECTQ k1+1, ymm, ymm L: [diff. reg. set] T: 0.23ns= 1.00c
AVX512_VP2INTERSECT :VP2INTERSECTQ k1+1, zmm, zmm L: [diff. reg. set] T: 0.23ns= 1.00c
Yes, that's right. 1 cycle throughput. ONE cycle. I can't... I just can't...
Intel was so bad at this that they dropped the instruction. And now AMD finally appears and shows them how it's done - 2 years too late.
At this point, I have no idea if VP2INTERSECT will live or die. Intel has historically led the way in terms of instruction sets with AMD playing copycat while lagging behind by a few years. Will AMD continue playing copycat and drop their amazing implementation of VP2INTERSECT? Or will they keep it alive going forward to Zen 6 and beyond? AMD has hinted to me that they may keep it, though I'm not entirely sure it's actually decided yet.
VP2INTERSECT doesn't look cheap to implement in hardware, but I suspect it uses the same hardware as VPCONFLICT given their similar functionality.
- Both VPCONFLICT and VP2INTERSECT have the same throughput at the 256-bit and 512-bit widths.
- The performance of VPCONFLICT has changed from Zen4 to match that of VP2INTERSECT.
In all likelihood, AMD redesigned their VPCONFLICT circuitry to handle VP2INTERSECT as well. And since they now have a design that handles both efficiently, I don't see any major reason for AMD to get rid of VP2INTERSECT for as long as they keep this piece of hardware. So even if AMD intends to kill it off in the future, they'll probably keep it around until the next major redesign of this execution unit.
Personally, I think VP2INTERSECT is a disgusting instruction. The way it encodes two mask outputs is out of line with all other (extant) AVX512 instructions. And because it fails to fall under any of the common "instruction classes", it likely needs to be specially handled by the decoder and possibly the uop schedulers as well.
In short, the instruction probably should never have existed in the first place in its current form. This may be one of the reasons Intel decided to get rid of it. It's unclear exactly what the original task was that it was meant for.
My prediction is that unless someone finds a major use for this instruction with AMD's fast implementation, it will eventually die. So if anyone actually likes this instruction, the timer starts now and will end before AMD's next major architecture redesign.
Putting aside the doubling in width, the vector port layout in Zen5 remains the same as Zen4. So there are still 10 data read ports shared across 4 execution and 2 store pipes.
So in the idealized case, this (10 inputs) runs at 4 instructions/cycle:
vfmadd213pd zmm{k}{z}, zmm, zmm ; 3 inputs (mask register does not count)
vaddpd zmm{k}{z}, zmm, zmm ; 2 inputs (destination register doesn't count since it's not read from)
vfmadd213pd zmm{k}{z}, zmm, zmm ; 3 inputs
vaddpd zmm{k}{z}, zmm, zmm ; 2 inputs
while in the worst case, this (12 inputs), runs at 2 instructions/cycle:
vfmadd213pd zmm{k}, zmm, zmm ; 3 inputs
vaddpd zmm{k}, zmm, zmm ; 3 inputs
vfmadd213pd zmm{k}, zmm, zmm ; 3 inputs
vaddpd zmm{k}, zmm, zmm ; 3 inputs
The difference being that the merge-masking turns the destination operand of the FADD into an extra input while the FMA always has 3 inputs.
However, I found it to be more difficult to hit the 10 port limit on Zen5:
- Because you need 4 x 512 to saturate the EUs, you are more likely to hit other bottlenecks first. (front-end, register pressure, etc...)
- Zen5 appears to be more capable of eliding reads from the register file. Perhaps it can cache inputs across multiple instructions. (though this is difficult to verify)
It's easy to hit the 10-port limit using only integer SIMD (8x ternlog will do it). But it's rather difficult to hit it using only floating-point. The higher latency of floating-point combined with the need to sustain 4 IPC meant that I would run out of registers long before hitting the 10-port limit. And if I reused inputs, the EUs seemed to be able to cache some of them to elide reads to the register file.
But with the help of stores, it's much easier to hit the 10-port limit with pure floating-point. A carefully written workload of 50% FADDs + 50% FMAs where no forwarding or input reuse is possible will degrade in performance by sprinkling in some vector stores. Nevertheless, it still took effort and was synthetic. Though while testing this, I did notice that it was possible to sustain 4 x 512-bit arithmetic + 1 x 512-bit store every cycle (5 IPC) if you don't exceed the 10-port limit.
So the 10-port limit remains an issue on Zen5, but less so than Zen4. Nevertheless, it does become a problem in heavily optimized code that saturates the 4 x 512-bit EUs as memory accesses will easily push the port requirements above 10 and cause pipeline bubbles.
Thus it is not possible to simultaneously sustain all of the following every cycle:
- 2 x 512-bit FADD
- 2 x 512-bit FMA
- 2 x 512-bit load
- 1 x 512-bit store
While something like this would be amazing for certain workloads, it remains too much to ask for as there are too many bottlenecks.
Last time with Zen4, I (correctly) guessed that the vector register file (VRF) is 192 x 512-bit based on a direct measurement of the vector reorder window.
The situation on Zen5 is more complicated. Direct measurements of the reorder window yielded:
| Observed Reorder Window | |||
| Strix Point P-core | Strix Point E-core | Granite Ridge | |
| XMM (128-bit) | 420 | 420 | 444 |
| YMM (256-bit) | 408 | 408 | 444 |
| ZMM (512-bit) | 252 | 252 | 444 |
Prior to AMD's disclosure of the architecture block diagram, I hypothesized a VRF of size 480 - 512 entries based on the measured reorder window of 444 instructions. However, Zen5 has added a non-scheduling queue (NSQ) of 96 entries before register renaming. This means that measured reorder capability cannot be directly used to measure the VRF size.
AMD has revealed that the VRF is in fact 384 x 512-bit. Once we factor in the 96-entry NSQ and the 32 ZMM architectural state, we get close to the observed reorder window of 444 instructions - for Granite Ridge at least.
The results on Strix Point are harder to explain. The large difference between the YMM and ZMM reorder window implies that the register file is only 256-bit wide with ZMM values taking 2 entries instead of 1. But why the difference between XMM and YMM and why both are smaller than Granite Ridge is harder to explain.
But on Granite Ridge, it's pretty impressive. A VRF of 384 x 512-bit is huge - 24 KB in size. That's half the size of the L1 cache!
And if that's not mind-boggling enough, if we extrapolate the following:
- 10 x 512-bit read ports
- 4 x 512-bit EU + 2 x 512-bit load / cycle
We can deduce that this 24 KB of storage has 640 bytes/cycle of read bandwidth and 384 bytes/cycle of write bandwidth.
A VRF of 384 x 512-bit is far greater than any other x86 processor to date:
| Architecture | Vector Register File |
| Skylake X Cannon Lake |
168 x 512-bit |
Ice Lake Tiger Lake |
224 x 512-bit |
| Alder Lake Sapphire Rapids |
320 x 256-bit 220 x 512-bit |
| Zen 1 | 160 x 128-bit |
| Zen 2 Zen 3 |
160 x 256-bit |
| Zen 4 | 192 x 512-bit |
Zen 5 (Strix Point) Zen 5 (Granite Ridge) |
< 384? x 256-bit 384 x 512-bit |
While I expected Zen5 to increase the VRF to handle the 4 x 512-bit execution throughput, I certainly didn't expect it to increase by this much. So I look forward to seeing this in the annotated die shots of the full Zen5 core.
Though it is worth mentioning that although Zen5 has drastically increased the VRF size (and blowing Intel out of the water in the process), the integer register file has not significantly increased from Zen4 (224 -> 240 entries) and thus remains smaller than Intel's latest.
Implications of the large VRF:
This massive increase of 192 -> 384 entries + NSQ is one of only two major improvements that Zen5 brings to 128-bit and 256-bit vector instructions. The other being the ability to do 2 x 128-bit or 256-bit stores/cycle.
It is likely that this massive VRF and reorder capability increase, (alone or in large part), is what gives Cinebench and CPU-Z their 10-15% IPC improvement since Chips and Cheese's analysis on Cinebench and CPU-Z point at the reorder buffer being the primary bottleneck.
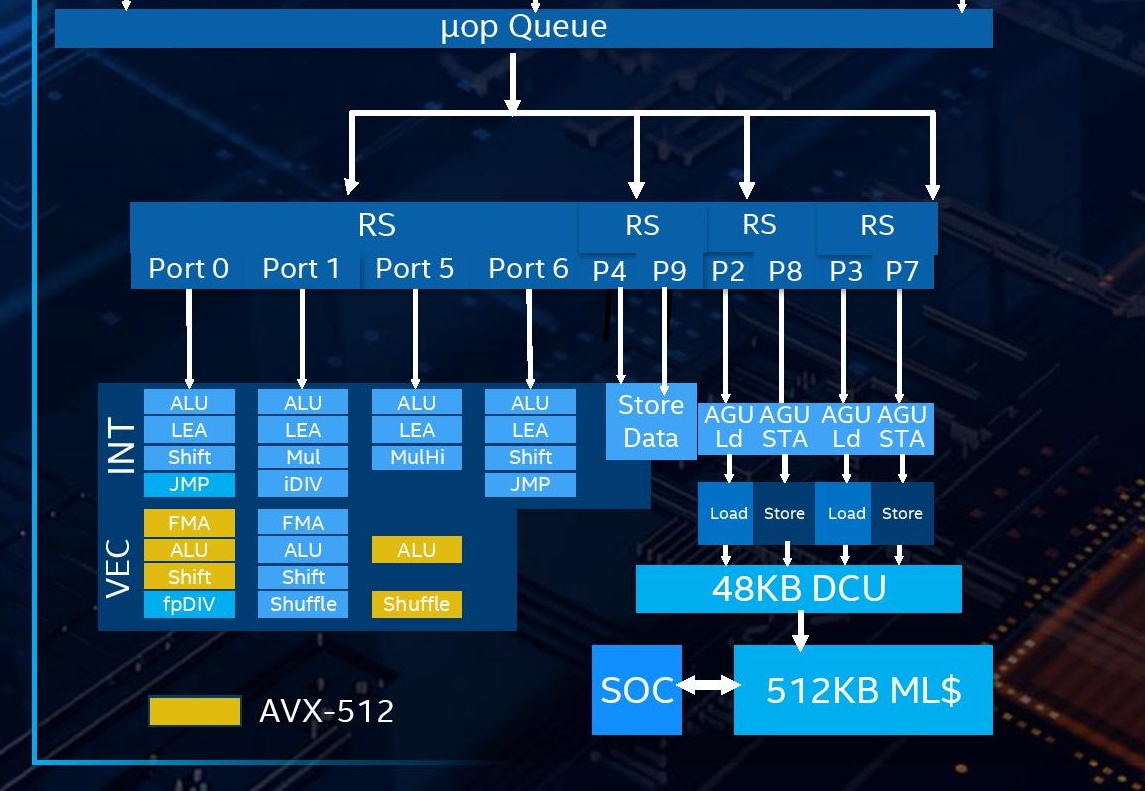
While this article is mainly focused on the vector unit and the AVX512, there's enough interesting changes in the back-end of the integer unit that I'll touch on as well.
|
|
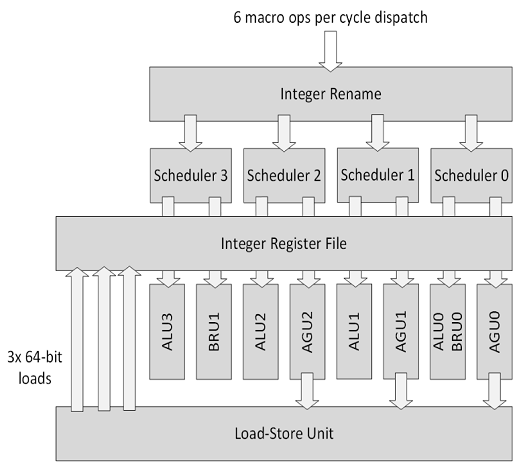
| Zen4's integer block diagram. (Source: Zen4 Optimization Manual) |
Both the leaked slides and the GCC patch revealed that Zen5 will be gaining two additional ALUs for a total of 6.
But what GCC's patch did not reveal is that those 2 extra ALUs are not "simple" ALUs. They are actually big ones.
Before we look into that, let's start with Zen4's integer execution layout.
Section 2.10 in the Zen4 Optimization Guide shows the architecture as:
- ALU0: add/logic, divide, branch
- ALU1: add/logic, multiply, CRC, PDEP/PEXT (all the 3-cycle instructions)
- ALU2: add/logic
- ALU3: add/logic
From this it's easy to see that ALUs 2 and 3 are cheap while ALUs 0 and 1 are expensive.
The two extra ALUs that Zen5 adds are not simple ALUs like Zen4's ALU2/3. They are actually closer to ALU1 in capability. In other words, they support all the "expensive" 3-cycle latency instructions - multiply, CRC, PDEP/PEXT.
In other words, Zen5 can multiply, CRC, and PDEP/PEXT all at 3/cycle.
Update August 16th: The official Zen5 optimization manual claims that PDEP/PEXT do not share ports with IMUL/CRC. So 3 of the ALUs can do IMUL/CRC while the other 3 can do PDEP/PEXT.
While retesting this, it took considerable effort to exceed 3 IPC by mixing IMUL and PEXT (maxing out at 3.5 IPC). In my initial tests months, I never exceeded 3 IPC and thus (incorrectly) assumed that all of these instructions shared the same 3 ports. When in reality, they do not share ports, but a different (unknown) bottleneck made it appear as though they shared ports.
So not only does Zen5 become the first P-core x86 CPU to run any of these instructions at more than 1/cycle throughput, it blows through that with a full tripling in throughput.
The 3x in multiply throughput has obvious gains in real-word code as a big usecase will be indexing into struct arrays. CRC and PDEP/PEXT are more niche but are very important to the workloads that need them.
The full capability of these 2 extra ALUs was not revealed in the GCC patch which says that multiply is still 1/cycle. When asked about this, AMD told me this error in the GCC patch was intentional to avoid leaking the true capability of Zen5 before they were ready to reveal it.
|
| Zen5's integer block diagram. (Source: "AMD Tech Day Zen5 and AMD RDNA 3.5 Architecture Update") |
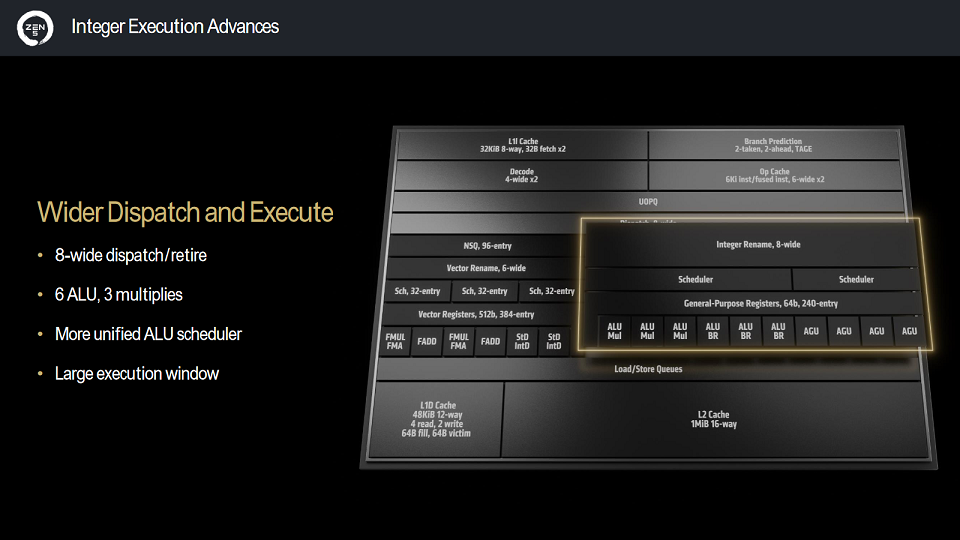
Further observations not revealed in the official architecture block diagram:
- All 3 of the integer MUL execution units are also capable of CRC, and PDEP/PEXT.
- The ALU scheduler is measured to be ~86 entries deep.
- The AGU scheduler is measured to be ~60 entries deep.
While Zen5 has 6 ALUs, I've found that it is not possible to sustain. Furthermore, I found it difficult to even exceed 5 IPC. Even the most synthetic of synthetics maxed out at 5.5 IPC - suggesting a bottleneck elsewhere which I have yet to determine.
5.5 IPC proves the existence of the 6 ALUs. But it also required a synthetic loop unrolled to nearly 1,000 instructions to achieve.
So the conclusion is that 5 IPC is realistic. But don't expect more than that outside of synthetics. I wouldn't even recommend compilers to think that 6 IPC is possible for their cost model calculations.
(Keeping in mind here that "IPC" refers to actual ALU instructions. Move-eliminated instructions do not count. And vector instructions are counted separately. It is possible to achieve 8 IPC if you use 0-uop instructions or if you combine integer and vector instructions.)
So we know that Zen5 triples the integer multiply throughput. But it's worth digging deeper since there's two kinds of multiplies here.
- Lower Half: Lower 64-bits of a 64 x 64-bit multiply. (2-operand IMUL)
- Full Product: 64x64 -> 128-bit (1-operand MUL/IMUL + MULX)
Modern CPUs have separate hardware for lower-half and upper-half multiplies. Meaning that a full product multiply is split into 2 uops which go to their respective units (with the upper-half having a higher latency).
In other words, modern processors (prior to Zen5) actually have 2 integer multipliers even though all the multiply instructions max out at 1/cycle.
Thus Zen5's expansion to 3 multipliers isn't as large as it would initially seem. And while all 3 of them can do lower-half multiplies, only one is capable of upper-half multiply. So Zen5 triples the throughput of lower-half multiply while full-product multiply remains the same at 1/cycle. Testing combinations of lower-half and full-product multiply instructions shows that the full-product multiply (MULX) consumes 2 of the 3 multipliers.
- 1 x IMUL + 1 x MULX every cycle is possible. (3 multiply uops)
- 2 x IMUL + 1 x MULX every cycle is not possible. (4 multiply uops)
Nevertheless, this is still a nice improvement and an arguably better utilization of the hardware.
Mixing of multiply types is rare. Most applications use entirely one or the other and will not mix both. I'm aware of only one major workload that mixes IMUL and MULX in close proximity. And my tests show overall IPC gains of that in excess of 35% over Zen4.
At this point, some readers will probably be wondering:
Why split a 64 x 64 -> 128-bit multiply into 2 separate uops? Isn't it more efficient to compute them together and return two registers?
Yes it sounds wasteful. In order to compute the upper-half of a multiply, you need to compute the lower-half to determine the carryout going into the upper half. Thus by separating a 64 x 64 -> 128-bit multiply into two separate operations, the bottom half ends up being computed twice.
But the reality with modern processors is that they are heavily optimized for their pipelines and scheduling. Uops are very RISC-like and generally cannot return two values at once as would be required by a full multiply instruction like MULX. So instead of using a single "fat" multiplier that takes two 64-bit integers and produces a 128-bit result that is written to two registers, they issue two separate "natural" uops each of which independently compute a different half of the 128-bit result.
Examples:
- AVX512-IFMA has separate instructions for the low and high parts of a 52 x 52->104-bit multiply.
- Intel's Ice Lake integer block diagram shows "MulHi" as a separate unit under port5.
- The ARM instruction set has separate instructions (MUL and UMULH) for the low and high parts of a 64 x 64 -> 128-bit multiply.
{kind=link}
It's unclear exactly when CPUs started doing this. Latency/throughput tables don't tell the whole story. Even though full-product multiply has been 2 uops since Sandy Bridge (2011), it's unclear if it had separate hardware for lower vs. upper half or if the extra uop is just for writing the extra output to the register file.
To say that Zen5's full AVX512 is impressive is an understatement. In a world where every % of performance matters and is hard fought for, we rarely see performance gains measured in "2x" instead of the usual "N%". And when this does happen, it's usually for very specific applications where a new instruction was added for them. Here, we see 2x across the entire vector stack.
While this isn't the first time AMD has doubled up their vector unit (they also did it in Zen2), this time hits different. When Zen2 doubled up the SIMD width from 128 to 256 bits, it was just a single step in a hopelessly long road to catching up to Intel's massive advantage with AVX512.
But this time, Zen5's improvement from 256 to 512 comes when Intel's struggles has forced them to backtrack on SIMD. The result is that not only has AMD surpassed Intel in their (formerly) strongest area, they have completely flipped the script on them. AMD's advantage over Intel today in SIMD is comparable to Intel's advantage over AMD in 2017 when it was Zen1 vs. Skylake X or the dark days of Bulldozer vs. Haswell.
But that only applies to the full Zen5 core on Granite Ridge. Meanwhile, Strix Point is somewhat of a mess. The nerfing of the vector unit goes beyond the 512-bit datapaths as the FADD latency and vector register file are also worse. And there's probably more that I missed. It's almost as if AMD took the full Zen5 design and decided to randomly knock things out until they met a certain silicon and power budget. Hybrid architectures are also undesirable for most HPC workloads, but of course HPC was never the intended market for Strix Point.
The biggest achilles heel of Zen5 is the memory bandwidth and the limited adoption of AVX512 itself. There simply isn't enough memory bandwidth to feed such an overpowered vector unit. And the amount of people who use AVX512 is rounding error from zero - thus leaving the new capability largely unutilized.
Memory bandwidth will not be easy to solve. We can expect Zen6 to improve things here with the new I/O and packaging improvments. But the bottleneck on AM5 and dual-channel DDR5 will remain. Perhaps a future platform with bigger caches (dual CCD X3D?) and 4-8 channels of CAMM memory will we see some light at the end of the tunnel.
As far as the adoption of AVX512 itself. The reason why it's low right now is largely because of Intel's fumbles. You can't introduce a shiny new instruction set, stack a ton barriers to using it, and expect people to quickly adopt it. And by the time AMD was able to do their implementation, Intel had already given up and bailed out.
So at no point in AVX512's history did both x86 CPU vendors support it at the same time. That sounds like a pretty big disincentive to developing for AVX512 right?
With Zen5, AMD finally delivers what Intel could not. A quality AVX512 implementation that not only bring substantial performance gains, but also avoids all the negatives that plagued Intel's early implementations.
Will that be enough to save AVX512? Will developers bite on that 2x performance? Only time will tell.
In an ideal world, Intel will support AVX512 on all their CPUs even if they need to nerf it on some of chips the same way AMD has done with Strix Point. But as of today, Intel seems committed to killing off AVX512 for the consumer market. Thus they are playing a game of whether they can hold out long enough for AVX512 to die.
However, Intel's ability to do this may be jeapardized by their recent (company-wide) problems which are almost certain to shed market share to AMD. And this does not bode well for trying to kill off AVX512. Regardless of what happens, I wish Intel luck. Competition is good for consumers.